Briefly about transformer’s evolution or why is softmax cool
scroll ↓ to Resources
Link to publicaiton: Briefly about transformer’s evolution or why is softmax cool | by Andrejs | Jan, 2025 | Medium
Note
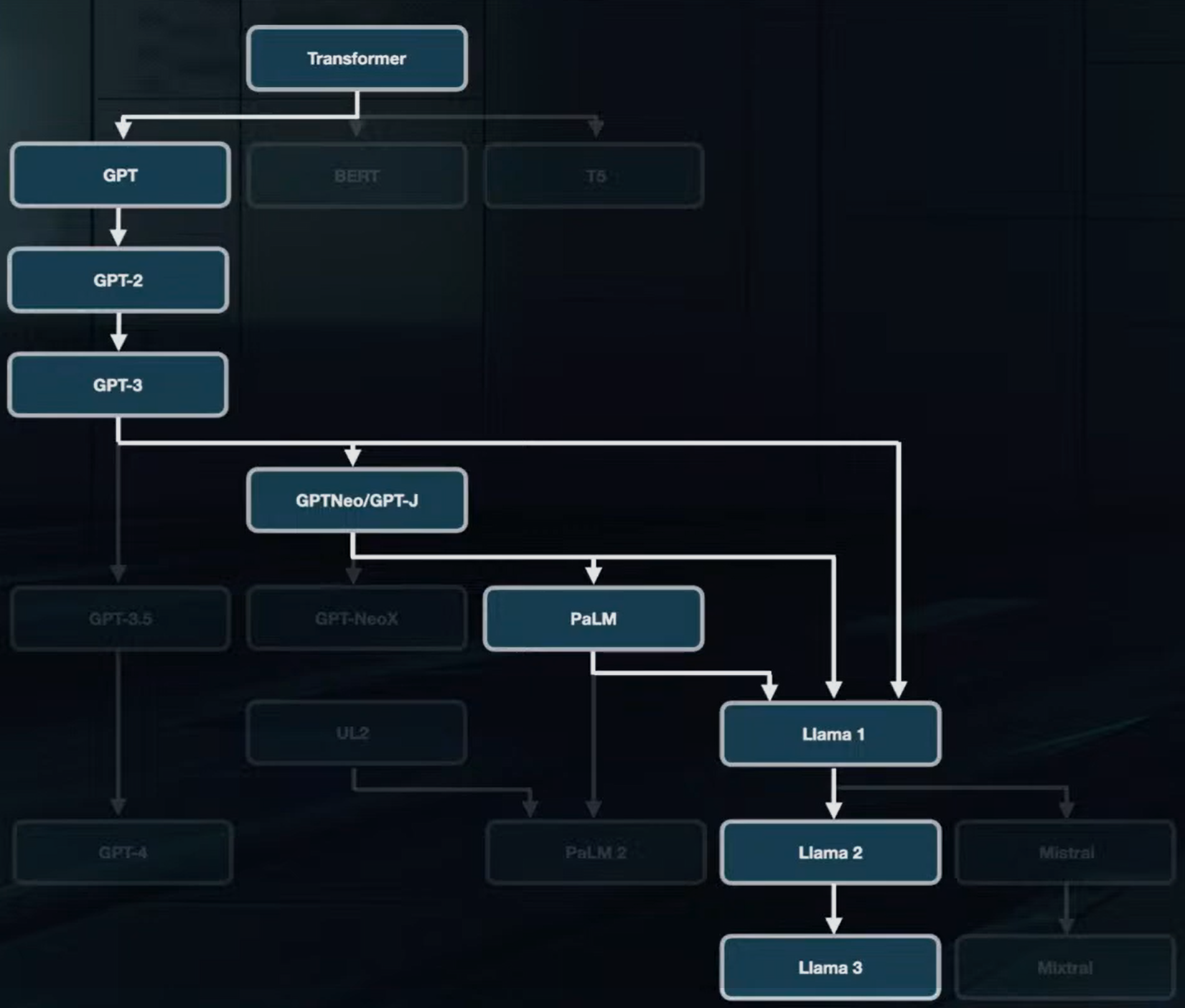
- transformer architecture has evolved significantly since that paper. I listed a few epochs in the field attributing them to specific models, but more often than not ideas are introduced in papers unrelated to models themselves. Worthwhile innovations are then implemented in SotA models and attributed to them. I don’t pay attention to numerical scale-up changes (layer numbers, attention heads, etc.)
- GPT-family models dropped the encoder part (BERT-like) already in GPT-1 (2018). activation function was changed from ReLU to GeLU (for good, but not forever).
- GPT-2 implemented pre-normalization when normalization before layers made training more stable, help to avoid learning rate warm-up. Pre-normalization is now a standard.
- GPT-3 (2020) on top of becoming a revolutionary “few-shot learner”, was designed to be less resource-demanding with sparse attention. The latter change didn’t stick and was abandoned.
- Prior to the GPT-3.5 there have been others GPT-like models (GPTNeo, GPT-J) with minor architectural experiments such as parallel layers (multi-head attention and feed-forward layer) for training and inference speed-up (not for model quality). Around that time positional encoding became RoPE.
- PaLM (2022) brought multi-query attention to the party and showed that feed-forward layer layers are better off without biases. It again changed the activation function standard to SwiGLU. The authors of this change present the following explanation for its efficiency - “We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.”
- The first Llama (2023) inherited from GPT-3, GPTNeo, PaLM and contributed RMSNorm - small modification of layer normalization.
- Next Llama 2 (2023) introduced grouped-query attention as an improvement over multi-query attention - also more for speed-up than performance.
- Finally, Llama 3 (2024) uses attention mask to prevent self-attenion between different documents in the context window during training.
- Do you know which component hasn’t been adjusted? The one that existed before the transformer itself. Right, softmax it is. The same one that pulls its weight since logistic regression. As LLMs are essentially big-big-big classification models, they need to convert pre-final outputs (logits) to “certainty” values. Yes, we can’t just design the model to predict the class itself (or token in the case of LLMs), because the backpropagation will not work (can you guess why?). So, we need to wrap feed-forward layer outputs into a function, which produces a “certainty” value with the following conditions: 1) non-negativity, 2) all outputs sum-up to one, 3) larger input results in larger output and, finally, 4) ensures partial derivative existence (yes, that would be a major problem with class labels predictions). softmax satisfies all needs and nice-to-haves and deserves its longevity thorough the history of shallow ML and neural networks.
- For the sake of argument, there are attempts to clip or modify softmax in the attention layer for various reasons. Here is a good read - a note by Eval Miller where he says that adjustments in softmax will allow better weights compression. Let’s wait for practice to test the theory…
Resources
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"