Harmful content detection system
scroll ↓ to Resources
Contents
- Clarifying Requirements
- Frame the Problem as an ML Task
- Data preparation
- Model development
- Evaluation
- Serving
- Other talking points
- Resources
Clarifying Requirements
Objective
We define our ML objective as accurately predicting harmful posts. The reason is that if we can accurately detect harmful posts, we can remove or demote them, leading to a safer platform.
Requirements
- Harmful content: Posts that contain violence, nudity, self-harm, hate speech, etc.
- Bad actors: Fake accounts, spam, phishing, other unsafe behaviors.
Misinformation is controversial and out of scope for this system design.
- Content can be text, image, video or any combination of those.
- The system should work with any language, but we can assume having a multi language model for that.
- Comments. author info, reactions
- Around 500 million posts per day, of which around 10k have labels.
- Users can report harmful content.
- If the post is removed, we provide users an explanation or link to the rules.
- Some threats must be real-time, such as violent content, Other threads can be handled via batch processing.
Frame the Problem as an ML Task
Inputs and Outputs
Choice: Fusing methods
To make accurate predictions, the system should consider all modalities. There are two fusing methods to combine heterogeneous data: late fusion and early fusion.
Late fusion
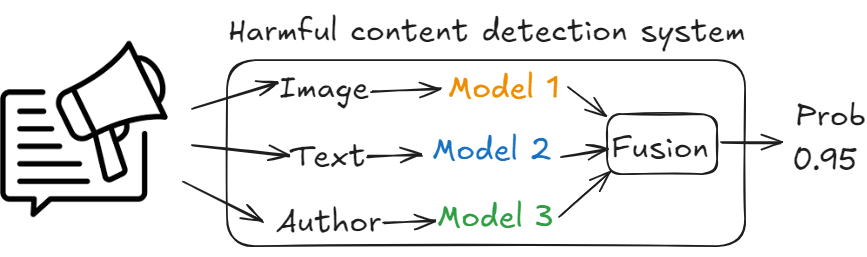
Process different input modalities independently using different models and then combine the predictions of each model for the final prediction.
- Advantage:
- Each model can be trained, evaluated and improved independently.
- Disadvantage:
- Separate training data for each modality is needed.
- Late fusion fails to detect cases where, each of the modalities contains unharmful content, unless combined. Think of memes with images and accompanying text.
Early fusion
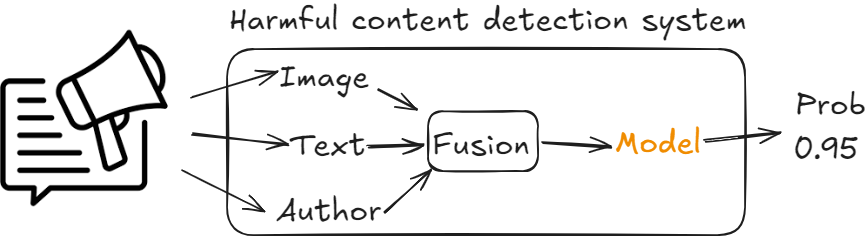
The modalities are combined first and then the model makes a prediction.
- Advantages:
- No need to collect separate data sets for each modality.
- Disadvantages:
- More challenging to learn complex relationships between modalities.
The early fusion method is preferred, because we need to capture posts that may be harmful overall. And besides this, with such an immense amount of data, the model should be able to learn the patterns pretty well.
Choice: ML approach
Single binary classifier
After fusing all the features, supply it to a single model which will output a single number.
As the model doesn’t discriminate categories of harm, this violates one of the requirements.
Binary classifier per category
One model will detect violence, another nudity, the third one - hate, and so on. This option will comply with the requirement but it is time consuming and expensive to train so many models.
Multi-label classifier
This will work as single model will output probabilities of each harmful category, but it can be a suboptimal solution, because Fused features, pre-processed in the same way, are used for different category classifications. Allowing separate preprocessing pipelines may yield better results.
Multi-task classifier
Multi-task classification strives to create a model which will learn multiple tasks simultaneously, allowing it to learn similarities between tasks and avoid unnecessary computations when a certain input transformation is beneficial for multiple tasks. Therefore, it requires two layers - shared layers and task-specific layers.
Shared layers
A set of hidden layers that transform input features into new ones. These newly transformed features are used to make predictions for each of the harmful classes.
Task-specific layers
These are independent classification heads transforming features in a way that is optimal for predicting a specific harm category.
Multi-task classifier is chosen for this problem.
High-level ML system
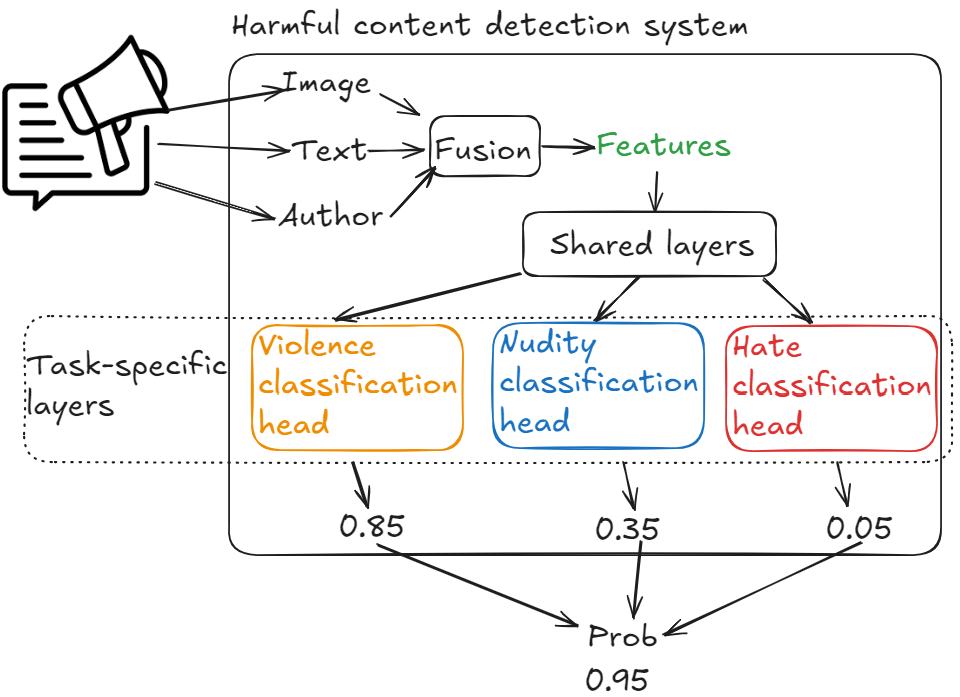
All post modalities are fused together to create features. Engineered features Undergo transformation in shared layers and emerge as embeddings. Each of the classification heads in task specific layers looks at those transformed features and makes their own prediction. After that we have a probability value for each of the charm category. We can apply some sort of heuristic to produce a single number out of multiple probabilities.
Data preparation
Available data
Users
| ID | Username | Age | Gender | City | Country |
|---|
Posts
| Post ID | Author ID | On-device | Timestamp | Textual content | Images or videos | Links |
|---|---|---|---|---|---|---|
| 1 | 1 | 73.93.220.240 | 1658469431 | Today, I am starting my diet. | http: //cdn.mysite.com/u1.jpg | - |
| 2 | 11 | 89.42.110.250 | 1658471428 | The video amazed me! Please donate | http: //cdn.mysite.com/t3.mp4 | gofundme.com/f/3u1njd32 |
| 3 | 4 | 39.55.180.020 | 1658489233 | What is a good restaurant in the Bay area? | http: //cdn.mysite.com/t5.jpg | - |
User-post interactions
| User ID | Post ID | Interaction type | Interaction value | Timestamp |
|---|---|---|---|---|
| 11 | 6 | Impression | - | 1658450539 |
| 4 | 20 | Like | - | 1658451341 |
| 11 | 7 | Comment | This is disgusting | 1658451365 |
| 4 | 20 | Share | - | 1658435948 |
| 11 | 7 | Report | violence | 1658451849 |
Feature Engineering
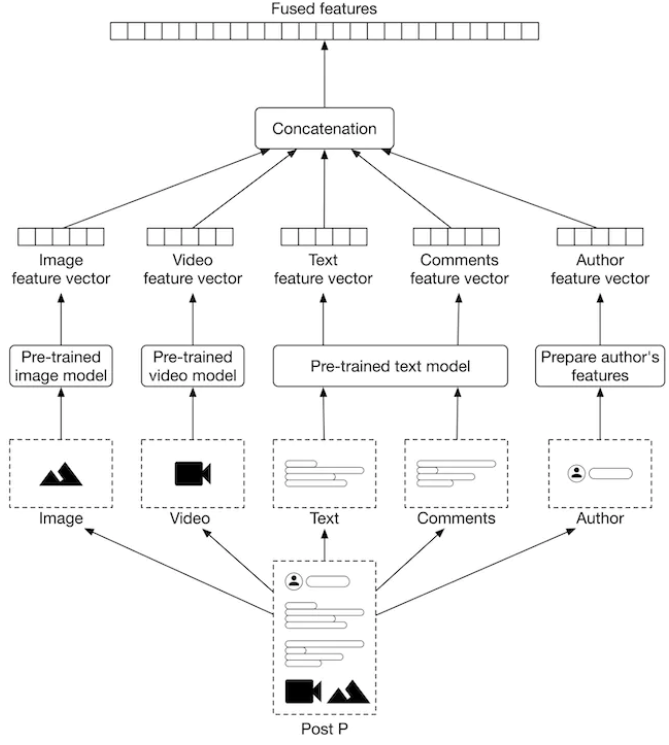
Each post contains several content types each with their own preprocessing and feature extraction steps
- Textual content
- Image or video
- User reactions to the post
- Author
- Contextual information
Textual content
- Pre-processing
- normalization
- tokenization
- Vectorization: Creates a meaningful feature vector using either statistical (Bag-of-Words, TF-IDF) or ML-based methods.
- Statistical methods do not encode the semantics of a text, therefore, we must use a ML-based method.
- Language model such as BERT is a large model, hence producing embedding takes time, which is not available during online prediction. In addition, BERT was trained on English-only data, so it will not produce good results for other languages.
- DistilBERT is optimized in such a way that if two sentences have the same meaning, but are in two different languages, their embeddings still is very similar.
Image or video
- Pre-processing
- decode, resize, normalize
- Feature extraction
- Use a pre-trained model to convert unstructured data into a feature vector. Viable options are CLIP visual encoder, SimCLR. For videos - VideoMoCo.
User reactions to the post
- Feature extraction
- The number of likes, shares, comments, and reports
- Similar to textual content, obtain embeddings for each comment and average them.
- Scale numeric values for better convergence
- The number of likes, shares, comments, and reports
Author
- Feature extraction
- Violation history
- Demographics
- Account information such as account age, number of followers and followings.
- Contextual information, such as time of the day and the device.
Joint feature engineering pipeline
Model development
Model selection
Neural network. Architecture is not detailed.
Model training
The model training happens in a standard way with forward propagation leading to prediction and measuring a loss function. then backward propagation to optimize the model parameters and reduce the loss function in the next iteration.
Constructing the dataset
- data annotation
- manual labeling
- ==slow and expensive, but good for Evaluation data to prioritize accuracy==
- natural labeling: Rely on users or reports to label posts automatically
- fast and suitable for training data assuming enormous dataset sizes
This way, the best model will pick-up such model weights from naturally labeled data. which will result in the smallest loss on manually labeled data
- fast and suitable for training data assuming enormous dataset sizes
- manual labeling
Choosing the loss function
- In multitask training, each task is assigned a loss function based on its machine learning category. In this system, all heads are binary classifiers, so they all can use a standard classification loss such as cross-entropy. So loss values are computed for each task and the overall loss is the result of combining task specific losses.
- A common challenge in training multi-modal systems is overfitting because one modality can dominate the learning process of all others.
Hyperparameter tuning
- Optuna, grid search
Evaluation
Offline metrics
PR-curve
Shows the trade-off between precision and recall of the model.
ROC-curve
Shows the trade-offs between the true positive rate (recall) and the false positive rate.
Online metrics
Prevalence
- the ratio of harmful posts which we didn’t prevent and all posts on the platform
- it treats harmful posts equally, but in practice, one harmful post with 100K views or impressions is more harmful than two posts with 10 views each. > use Harmful impressions==
Harmful impressions
Valid appeals
- Percentage of posts that were deemed harmful, but appealed and reversed.
Proactive rate
- Percentage of harmful posts found and deleted by the system before users report it.
User reports for harmful category
Serving
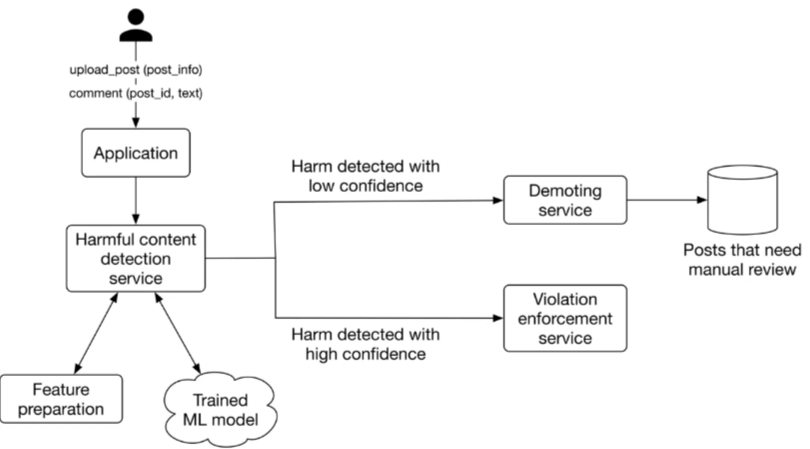
- After a new post appears, the service predicts the probability of harm.
- If the harm is detected with high confidence, Violation enforcement service removes the post right away. It also notifies the user why the post was removed.
- If the harm is detected with low confidence, the demoting service temporarily demotes a post and decreases its chance to spread among users. The demoted post is Scheduled for manual review by humans. The review team manually reviews the post and labels it. Labeled posts are used for future training and model improvement.
Other talking points
- Handle biases introduced by human labeling
- Adapt the system to detect trending harmful classes (e.g., Covid-19, elections)
- How to build a harmful content detection system that leverages temporal information such as users’ sequence of actions
- How to effectively select post samples for human review
- How to detect authentic and fake accounts
- How to deal with borderline contents, i.e., types of content that are not prohibited by guidelines, but come close to the red lines drawn by those policies.
- How to make the harmful content detection system efficient, so we can deploy it on-device
- How to substitute Transformer-based architectures with linear Transformers to create a more efficient system
Resources
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"