decoding strategy
scroll ↓ to Resources
Contents
- Note
- Decoding strategies
- [[#Decoding strategies#Constrained decoding|Constrained decoding]]
- Resources
Note
- Pre-final output of the LLM is a vector of probabilities from softmax layer: for each token in its tokenizer’s vocabulary. In order to show textual representation to a user, at each step, the system must choose the next token. The process is called sampling or sequence decoding.
Decoding strategies
- pure sampling - sample according to the distribution: token with N% probability after softmax is sampled by the system with N% probability
- greedy sampling - always choose the highest probability token. This gives reproducible result, but it is more boring and also lower quality (“likelihood trap”) ^42d3a3
- in that case softmax temperature doesn’t affect the result, because it will not change the argmax token
- beam search - at each step we save k most probable token sequences down to a given number of steps exploiting the idea, that taking NOT the most probable token at step N, still can lead to the largest overall likelihood for the whole sequence of generated tokens.
- This allows having a wider search space, but it also increases computational burden and often results in sequences with repeating tokens.
- To reduce the latter problem, one can use repetition and frequency fines.
- is not used on practice for LLMs, cause gives suboptimal results
- This allows having a wider search space, but it also increases computational burden and often results in sequences with repeating tokens.
- temperature sampling - randomly pick a token while taking into account given probability distribution. Same as for pure sampling, but this method is regulated by the softmax temperature parameter T.
- When T is zero, it becomes Greedy decoding.
- When the temperature is very high, all probabilities are almost equal - then it’s random sampling.
- top-k sampling - only consider top-K most probable tokens, normalize their probabilities to 1, other tokens are neglected
- the entropy of human speech (text) is dependent on which token\word we are at. There are moments when predicting the next word is trivial and there are cases, when it is very hard. ==therefore, having a constant K is not optimal== as we sometimes take too many and sometimes too few. This issue is resolved by top-p sampling
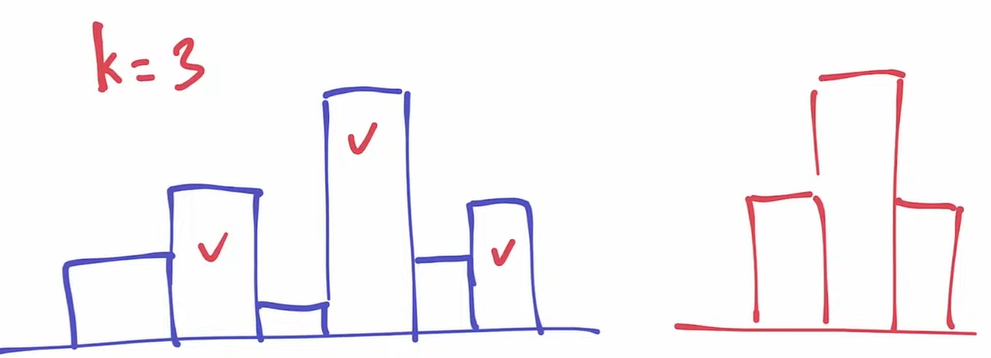
- the entropy of human speech (text) is dependent on which token\word we are at. There are moments when predicting the next word is trivial and there are cases, when it is very hard. ==therefore, having a constant K is not optimal== as we sometimes take too many and sometimes too few. This issue is resolved by top-p sampling
- top-p sampling (nucleus sampling) - instead of a fixed number of most probable tokens, add to the sampling set every token (in the order of probability) until the total probability exceeds the hyperparameter p (e.g. 0.95)
- this is currently the standard decoding strategy unless speculative decoding is used for speeding up the inference
Constrained decoding
Resources
- Decoding Strategies in Language Models | Rajan Ghimire
- THE CURIOUS CASE OF NEURAL TEXT DeGENERATION
- Dummy’s Guide to Modern Samplers
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"