prefix caching
scroll ↓ to Resources
Note
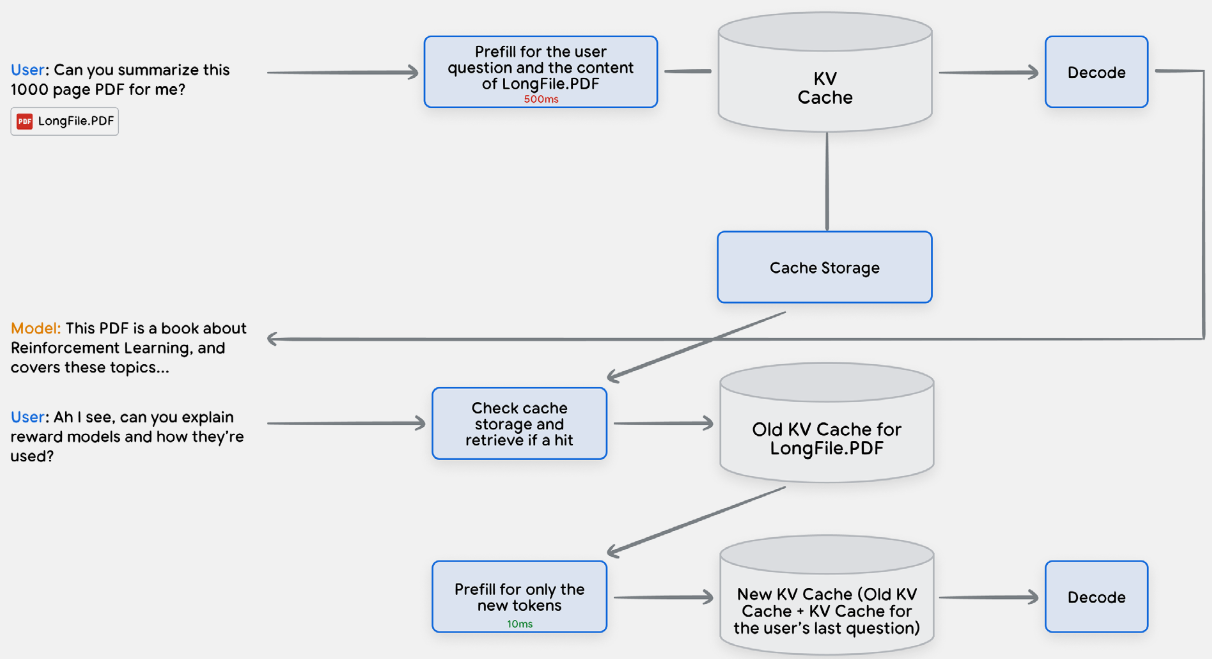
- prefill operation - Calculating the attention key and value scores (for the input we are passing to the LLM) - is one of the most compute-intensive and slowest operations in LLM inference
- The output of the prefill are the attention key and value scores for each layer of the transformer for the entire input.
- KV-cache allows to avoid recalculating attention scores for the input on each autoregressive decode step.
- prefix caching refers to the process of caching the KV-cache itself between subsequent inference requests in order to reduce the latency and costs of the pre-fill operation.
- LLM-chatbots with multi-turn conversations and large document/code uploads - are applications which naturally benefit from the prefix caching
- For it to be effective, the input structure and schema must remain prefix caching friendly: do not alter the prefix in subsequent requests as this will invalidate the cache for all the tokens that follow.
- As an example, putting a fresh timestamp at the very beginning of each request will invalidate the cache completely
Resources
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"