reward model
scroll ↓ to Resources
Note
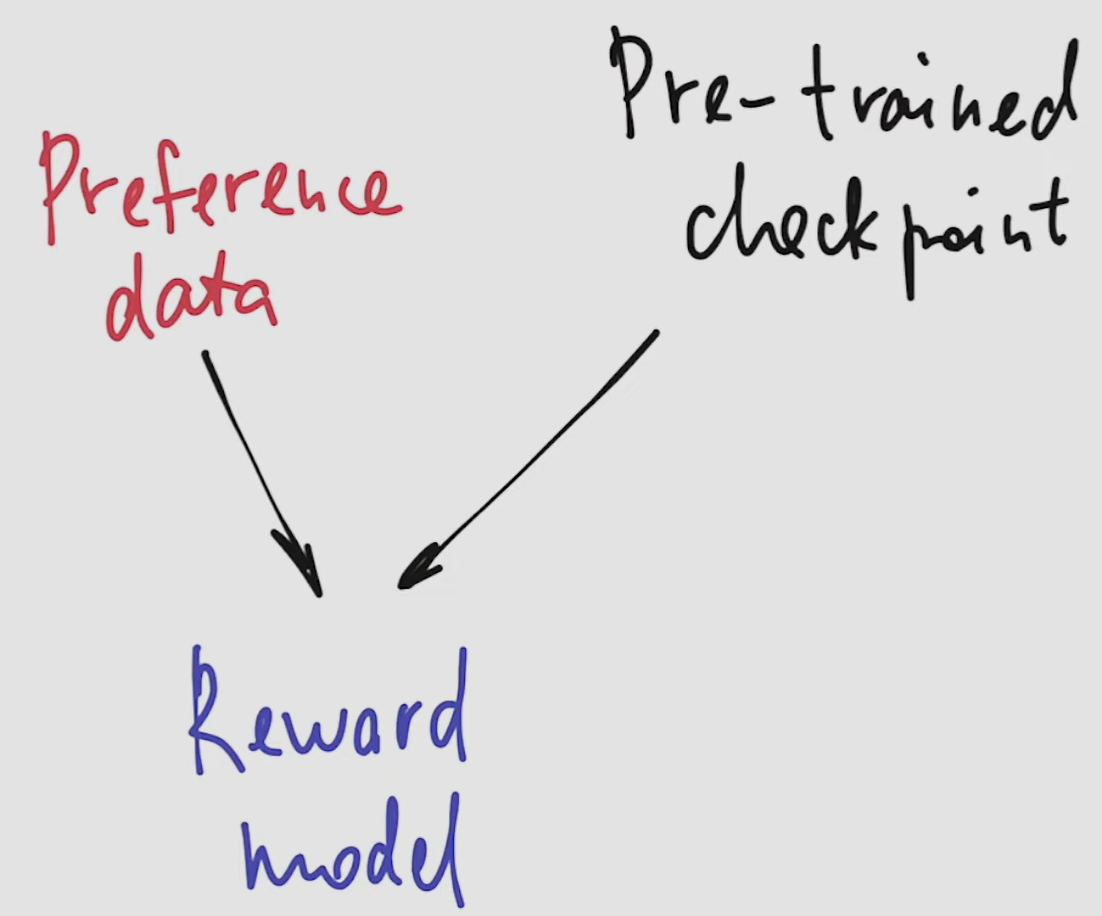
- reward model is the result of training on top of the pre-trained LLM checkpoint
- for any pair (instruction, result) predict a number (Reward Score) denoting how good is the result for this instruction - assigns a numerical score to model outputs based on their alignment with human preferences and values. The higher the score, the higher is the estimated degree of alignment.
- use human-annotated data with several ranked responses for each given instruction, for instance:
- in practice, there can be up to 9 ranked responses, some of which can be excluded if too hard to rank.
- response can be optionally added by human annotators to improve one of the existing responses
- having such a model, we can select the best result from several options or use it for RLHF
How to obtain a reward model
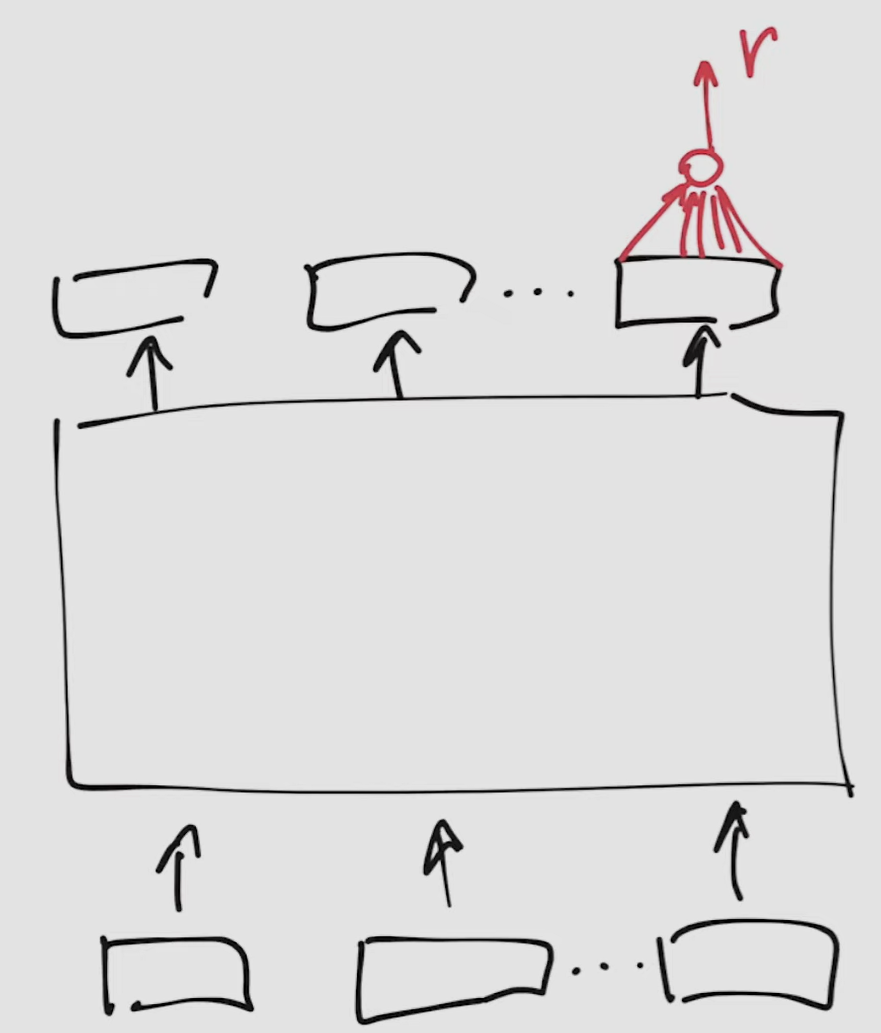
Architecture
- alter the transformer architecture by substituting the fully-connected layer with a single neuron, which output will be a number from to - our Reward Score (RS)
- this is done only for the last output token in sequence, where all output tokens are already known.
Preference Data
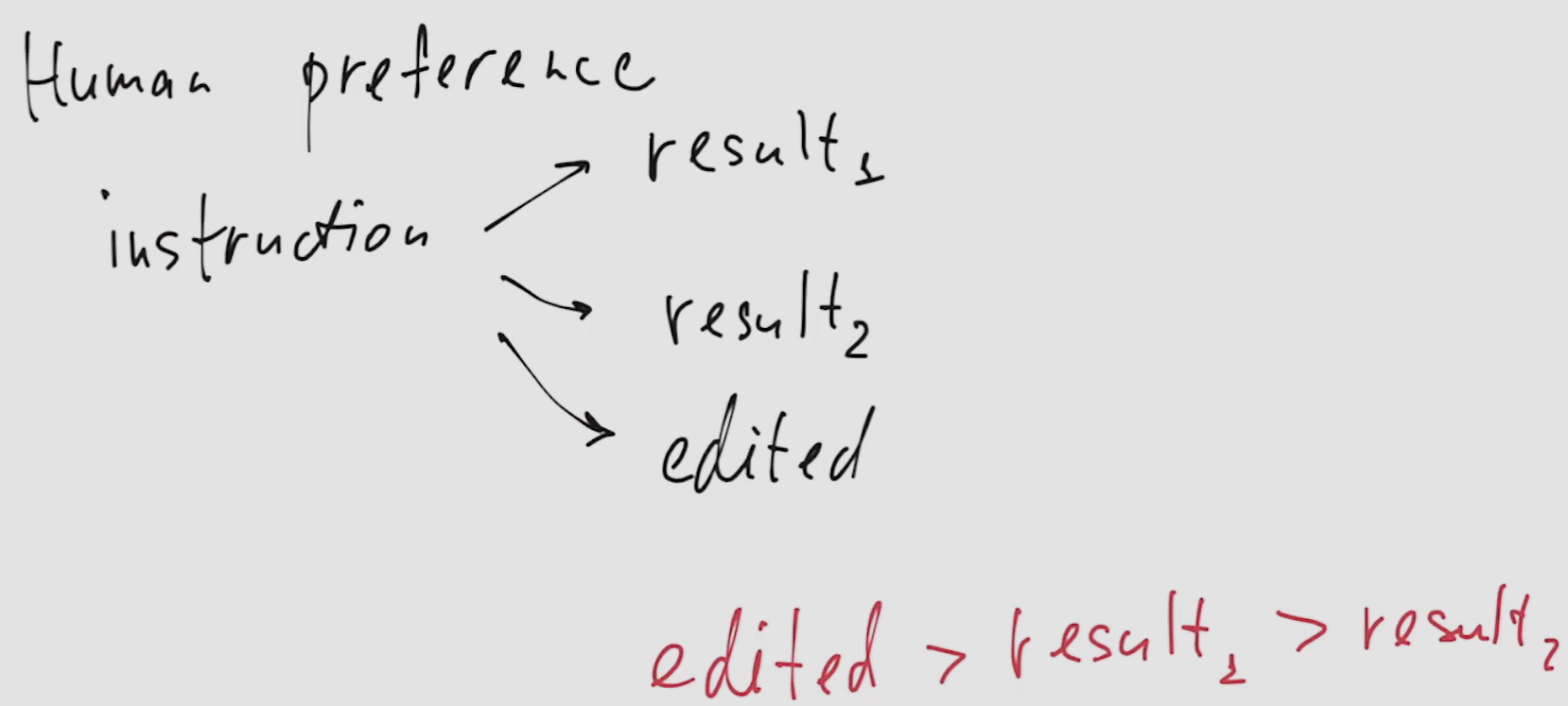
- Human preference data: several result candidates for each input instruction, ranked, but their rank is not quantified exactly.
- Additionally, labelers were allowed to edit one of the candidate results to make it the best among the three
Preference model
- several models exist, the one explained here is the Bradley-Terry model
- it claims: the probability that user prefers result y2 to result y1 is equal to where is the reward and where is the output of that single neuron
- this definition ensures it takes a value from to
- after math transformations we get that which is from 0 to 1
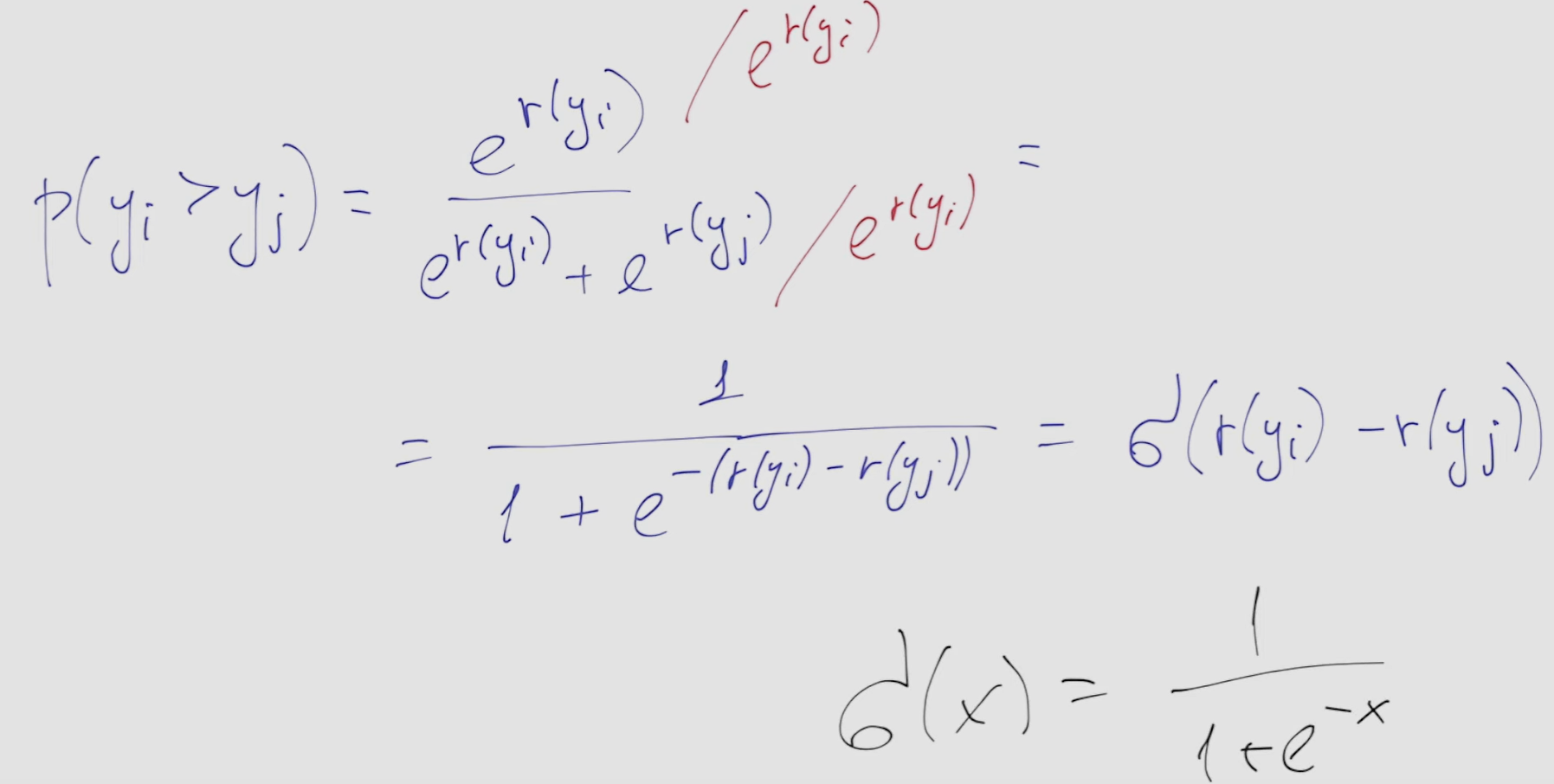
- given preference with ranked results (that is we know that ) and knowing from the the above that this probability is we can maximize this value while training the model with single neuron
- in practice we minimize the negative log of that. The optimum of this function is in 0 and it is reached only if . So we train the model to have the good response to have much higher score than the bad response, irrespectively of their absolute values.
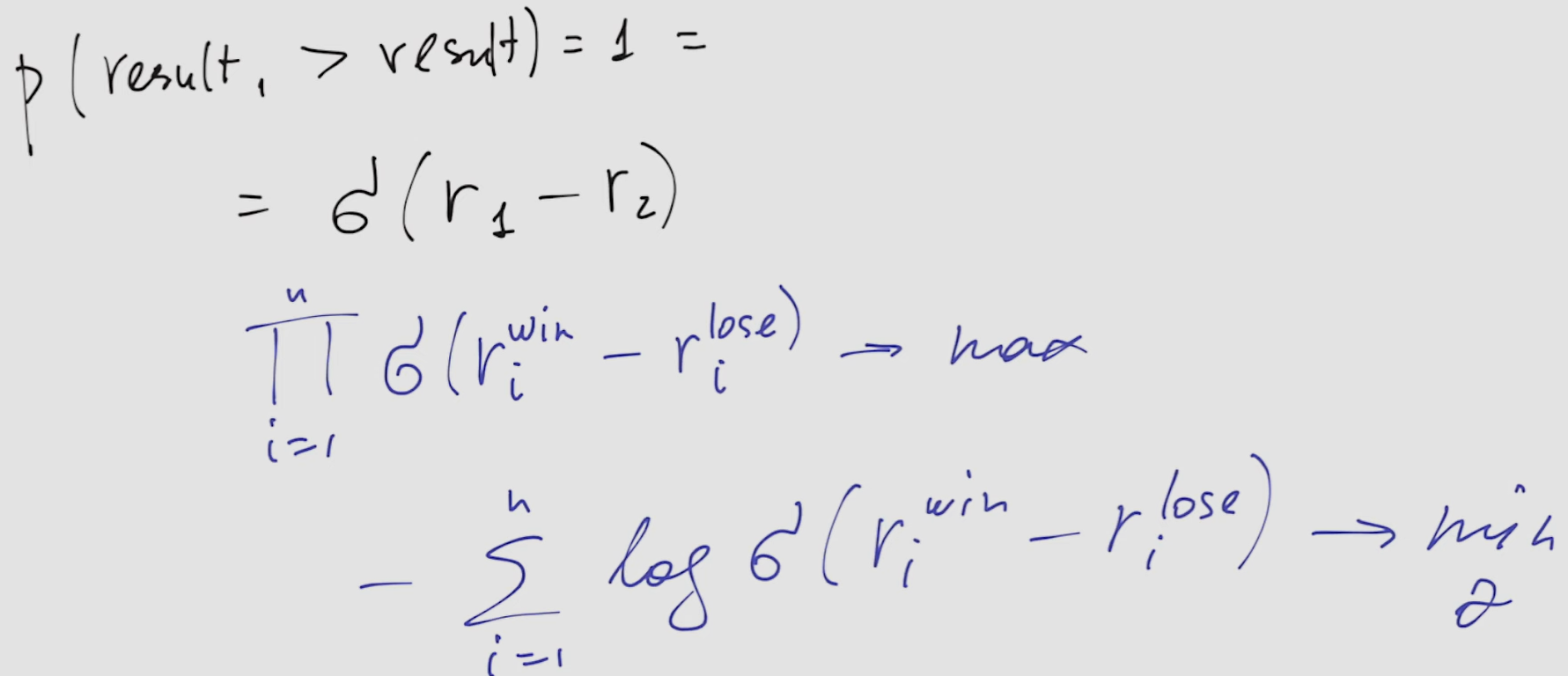
- Train a reward model using checkpoint of a pre-trained model and preference data
Resources
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"