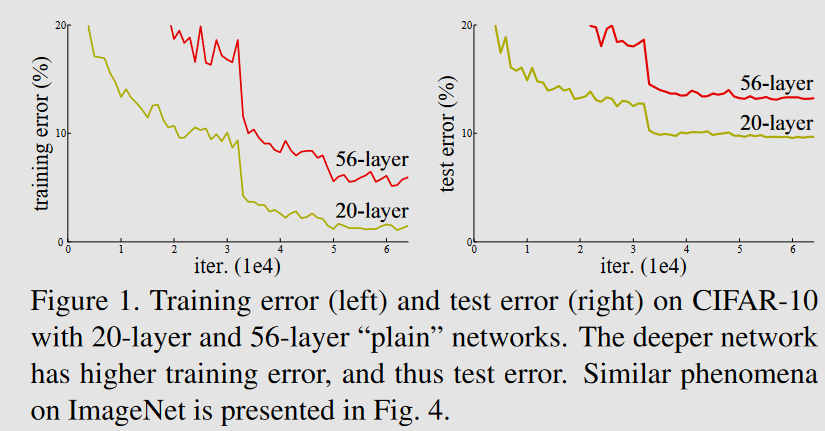
No, because then the training set error would be lower for the larger network.
56-layered network could have 36 “empty” layers not doing anything and then 20 extra layers which would do the job, but that’s not happening with “plain” networks
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"