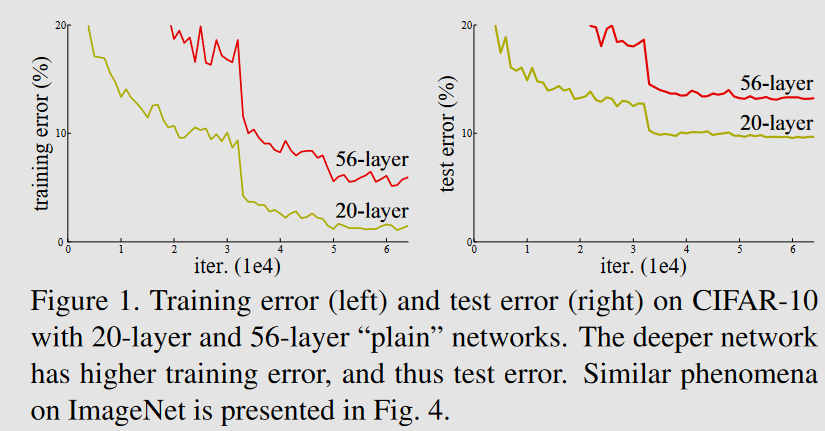
training degradation Notes Authors of [1512.03385] Deep Residual Learning for Image Recognition noticed that deeper networks not always give better testing (but also training) accuracy. why is that? ==can be an overfitting issue?== No, because then the training set error would be lower for the larger network. 56-layered network could have 36 “empty” layers not doing anything and then 20 extra layers which would do the job, but that’s not happening with “plain” networks to prevent training degradation the authors proposed to use the skip connection method Resources Links to this File table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"