byte pair encoding
Note
- iterative tokenization method for LLM, alternative to word- or character-level encoding
- algorithm of data compression
- greedy algorithm, it does not return back to fix non-optimal decision upstream
- stopping criteria: number of merging operations
- digits are individual tokens, otherwise popular numbers would join into tokens: constants like pi, human age numbers, etc.
- Another subword tokenization algorithm is WordPiece. It also starts with a vocabulary of all the characters in the training data. But it uses a statistical model to choose the pair of characters that is most likely to improve the likelihood of the training data until the vocab size is reached.
- The original BPE algorithm only allowed token merging inside words, but later approaches can sometimes allow this: For example, an LLM can have
import pandas as pdas one token.
Advantages
- It is an iterative algorithm and if we do it long enough, the distribution of tokens converges to uniform distribution. This leads to more balanced classes, which is advantageous for prediction tasks.
- If the input word is rare, it shouldn’t collapse to a token easily, but if it consists of popular sub-words, it is likely that the meaning of the word will be derived by the network from its parts (hair-dresser).
- open vocabulary ⇒ tokens for unknown characters (depends on the implementation though)
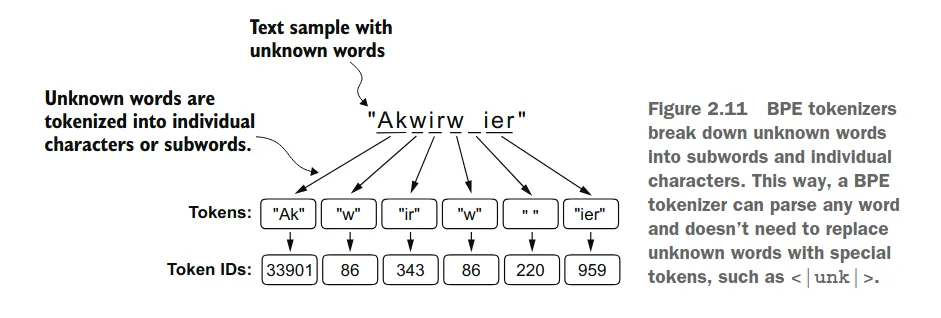
Disadvantages
- BPE is frequency-based, so words and subwords originating from languages that are not as widespread as English may be mercilessly cut into pieces, potentially damaging the LLM’s multilingual proficiency. With this in mind, some LLM creators spend additional effort to ensure a more equal representation of different languages and writing systems in the vocabulary.
Naive algorithm
See some details and realistic implementation intricacies in GPT-2 tokenizer details
Training a tokenizer
- Original text of length 533
- converted to the UTF-8 bytes sequence of length 616, because UTF-8 is variable length encoding of 1 to 4 bytes per character. Our vocabulary size is now 256 with possible tokens from 0 to 255.
- Iterate:
- find the most frequently appearing pair of bytes: in this case the pair is
(101, 32)which denotese(appears 20 times). - substitute all occurances of (101, 32) for a new token 256 ⇒ total sequence length compressed to tokens.
- next iteration where all newly created tokens are available for compression too

- find the most frequently appearing pair of bytes: in this case the pair is
- the number of iteration is a hyperparameter that can be tuned for optimal results: the more iterations the larger the vocabulary, the shorter the sequence.
- GPT4 uses ~100k tokens


sentencepiece tokenizer
Unlike tiktokenizer it runs BPE on unicode directly (unless for some very rare cases) and has a predefined vocabulary size
Decoding
- given a list of integers in the range
[0, vocabulary_size], return a text. - not all token sequences are valid UTF-8 byte strings, so they can’t be decoded exactly
- such wrong bytes are substituted with a special symbol �
Encoding
- given a string, return a list of integers
- go through the identified pairs of bytes and merge them
GPT-2 tokenizer details
- from Language Models are Unsupervised Multitask Learners
- the inference code GitHub - openai/gpt-2”
- training code wasn't released, so we don’t know which tricks were applied
- GPT2 encoder contains 50257 tokens: 256 original byte tokens + 50k merges + 1 special token
< |endoftext| >used to delimit documents in the training set
BPE including many versions of common words like
dogsince they occur in many variations such asdog.dog!dog?. This results in a sub-optimal allocation of limited vocabulary slots and model capacity. To avoid this, ==we pre-vent BPE from merging across character categories for any byte sequence==. We add an exception for spaces which significantly improves the compression efficiency while adding only minimal fragmentation of words across multiple vocab tokens.
- gpt-2/src/encoder.py at 9b63575ef42771a015060c964af2c3da4cf7c8ab · openai/gpt-2 · GitHub
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")- chunks the text prior to encoding, all parts will be independently encoded and the resulting token lists joined.
- this forces that some merges will never happen
- GPT2 and GPT4 tokenizers can be compared using Tiktokenizer library
Resources
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"