image retrieval
scroll ↓ to Resources
Contents
- Note
- Training
- [[#Training#Dataset splitting|Dataset splitting]]
- [[#Training#Training|Training]]
- Metrics
- Loss functions
- [[#Loss functions#Contrastive loss|Contrastive loss]]
- [[#Loss functions#Triplet loss|Triplet loss]]
- [[#Loss functions#Range loss|Range loss]]
- [[#Loss functions#Margin loss|Margin loss]]
- Sampling methods
- [[#Sampling methods#Hard Positives and Hard Negatives|Hard Positives and Hard Negatives]]
- [[#Sampling methods#Semi-hard Negatives|Semi-hard Negatives]]
- [[#Sampling methods#Distance Weighted Sampling|Distance Weighted Sampling]]
- Resources
- [[#Resources#Datasets|Datasets]]
Note
- Applications
- Object retrieval applications such as face recognition cannot be practically done assuming an underlying classification task.
- requires retraining when new classes added
- requires many data points for each class (N face photos from different angles, with\without beard\glasses, different lighting, …)
- undefined class for all objects not belonging to any given class
- classification for millions of classes are not feasible (and we know that face detection systems work for everyone unconditionally)
- Therefore, another approach is used:
- During Training: work with triplets of data samples (anchor , positive and negative examples) and train the model to produce such embeddings that their distance will be such that is small and is large
- the exact definition of what is small and large and how to make the model learn such vector representation depends on selected loss function, ML metric
- some Loss functions and Sampling methods assume not triplets, but sets of four objects in each training iteration
- During inference:
- pass the input object through the backbone network to calculate its vector embedding
- normalize the embeddings
- compute distances to existing database entries and decide which entries to select (e.g. k-nearest neighbors-like approach with Faiss, cosine similarity or another similarity distance)
- During Training: work with triplets of data samples (anchor , positive and negative examples) and train the model to produce such embeddings that their distance will be such that is small and is large
- Currently, one is unlikely to train models from scratch, but rather use existing foundation models such as DINOv2 by Meta AI in transfer learning or fine-tuning modes
Training
- three (anchor, positive, negative) or sometimes more samples are passed through the same backbone network
- the idea of siamese neural networks where same weights apply to all inputs
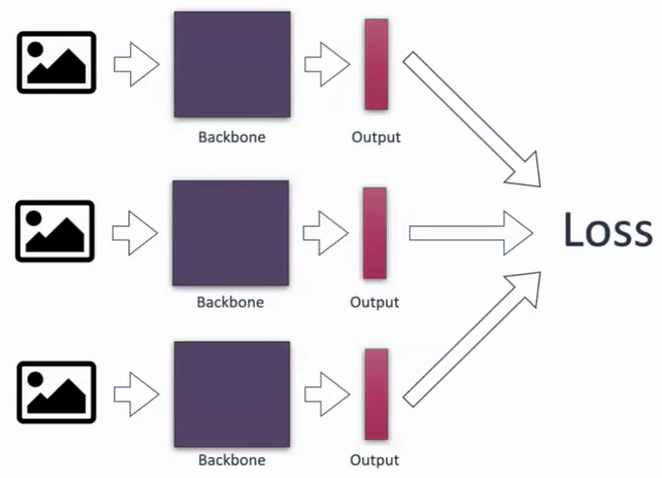
- the idea of siamese neural networks where same weights apply to all inputs
Dataset splitting
- Unlike for classification, the dataset splitting happens vertically that is some classes fully go into train only, some into validation and some into test set.
- In addition to that validation and test set are split into Query and Retrieval sets . This puts an additional requirements, that each class\object must have at least 2 samples.
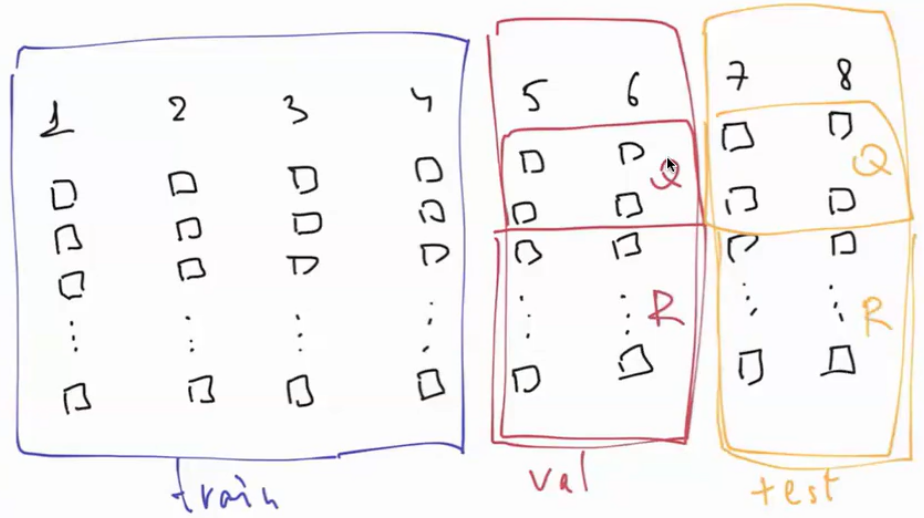
- In most applications the best split is such that one sample goes into Query, the rest - into the Retrieval set. The bigger is your Q - the better, but ==with smaller R the overall task becomes simpler==.
- If R has 100 images, N of them belong to the object and only few of them do not belong to the object, but very similar to it ⇒ this task is much simpler than if you have 100k images with the same N, belonging to the object, but now thousands more similar, but false positives.
- As long as you control the size of the Retrieval set it is easier to achieve promised accuracy of the system.
Training
- For each sample in the Query set, we evaluate how many of the object’s samples in the retrieval set were fetched among our k closest total samples fetched.
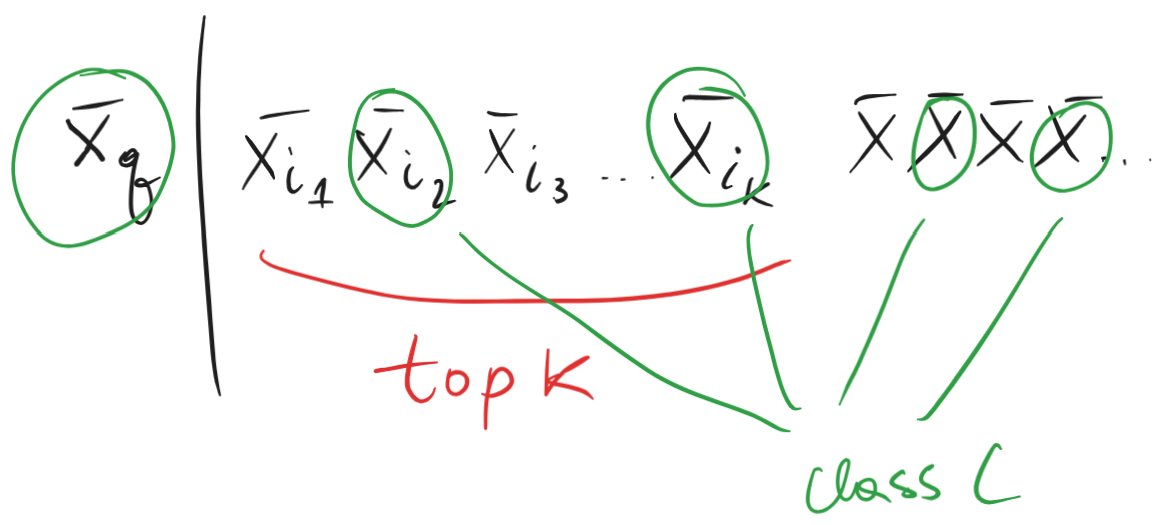
- is an important parameter. Although k=1 seems logical it may be:
- too strict for some applications: for street-to-shop app it is ok to show 5 images on the screen, if any one of them is a match to what user searched for
- unindicative during training: with k=1 metrics such as recall@k and precision@k will not evolve for very long time (potentially never)
Implementation tips
Metrics
- recall@k and precision@k

- : elements from the , which according to the model belong to class C
- : all class C objects in the whole Retrieval set
- if k > |C|, precision 1 is unreachable, 1/k is max possible value
- another metric also called recall@k
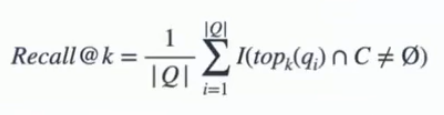
- summation over each element of the Query set: the indication function (1 if condition is true, 0 otherwise)
- the condition is that contain at least 1 object of class C
- how often on average we pick at least 1 out of k elements correctly
- with increasing k, recall@k can only grow or stay the same, that is the task becomes easier, because you only need 1 out of k elements to be true positive
- summation over each element of the Query set: the indication function (1 if condition is true, 0 otherwise)
- not being ideal metrics, still, with fixed Retrieval set and - the higher precision and recall the better
Loss functions
- Need to define such a loss that during training it will push anchor and positive example closer together and make negative example further away
- the loss function is now dependent on multiple objects in the batch. this affects also the way of Dataset splitting and Sampling
Contrastive loss
Triplet loss
Range loss
Margin loss
Sampling methods
- Due to the way Loss functions are constructed, sometimes gradients will be 0 with no update needed resulting in inefficient training
- We want such sampling that the training is hard
- For most sampling methods holds that bigger batch size allows more precise implementation of sampling method, resulting in better resulting metrics
- to combat this effect: Cross-Batch Memory for Embedding Learning
Hard Positives and Hard Negatives
Semi-hard Negatives
- taking too easy or too hard examples both make training go slow due to noisy or vanishing gradients
- take negatives which are already further away than positives from the anchor
- desired condition already satisfied, except for the effect of the parameter

- desired condition already satisfied, except for the effect of the parameter
Distance Weighted Sampling
- advanced method to sample objects with different distances probabilistically
- inversely proportional to the probability of such distance: the more often two images are at this distance, the less we sample objects at such distance
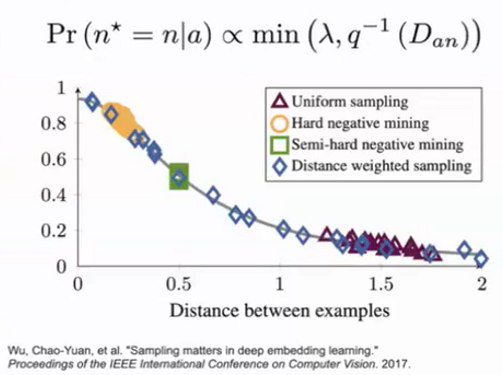
- inversely proportional to the probability of such distance: the more often two images are at this distance, the less we sample objects at such distance
Resources
Datasets
- Stanford Online Products Dataset | Papers With Code
- GitHub - CompVis/metric-learning-divide-and-conquer: Source code for the paper “Divide and Conquer t…
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"