Retrieval-Augmented Generation
scroll ↓ to Resources
Contents
- Note
- Vanilla RAG
- [[#Vanilla RAG#Re-ranking|Re-ranking]]
- [[#Vanilla RAG#Full MVP vanilla RAG|Full MVP vanilla RAG]]
- Evaluating information retrieval
- Challenges with RAG
- Advanced RAG techniques
- Other topics
- Resources
Note
- RAG is stitching together information retrieval and generation parts, where the latter is handled by LLMs.
- Tendency for longer context length does not undermine the importance of RAG
- evaluation is a crucial part of RAG implementation
- RAG >> fine-tuning:
- It is easier and cheaper to keep retrieval indices up-to-date than do continuous pre-training or fine-tuning.
- More fine-grained control over how we retrieve documents, e.g. separating different organizations’ access by partitioning the retrieval indices.
One study compared RAG against unsupervised finetuning (aka continued pretraining), evaluating both on a subset of MMLU and current events. They found that RAG consistently outperformed finetuning for knowledge encountered during training as well as entirely new knowledge. In another paper, they compared RAG against supervised finetuning on an agricultural dataset. Similarly, the performance boost from RAG was greater than finetuning, especially for GPT-4 (see Table 20).
Vanilla RAG
- Simplest pipeline for retrieval with bi-encoder approach, when context documents and queries are computed entirely separately, unaware of each other.
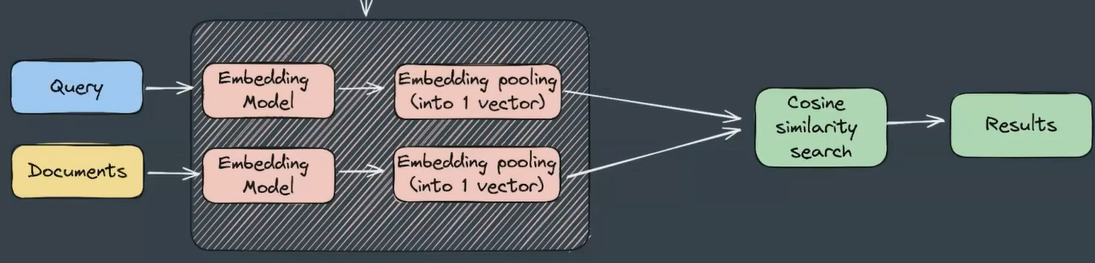
- At larger scales one needs a vector database or an index to allow approximate search so that you don’t have to compute all cosine similarity between each query and document
- Promoted by LLM, approximate search is based on dense representation of queries and documents in latent fixed vector space
- Compressing hundreds of tokens into a signal vector means losing information.
- encoding is mainly supervised via transfer learning (text embedding encoder-style transformer models)
- Vector index (IVF, PQ, HNSW, DiskANN++)
- Promoted by LLM, approximate search is based on dense representation of queries and documents in latent fixed vector space
- vector search is always combined with keyword search, which help handling specific terms and acronyms. Their inference computational overhead is unnoticeable, but the impact can be unbeatable for certain queries. Good old method is BM25 (TF-IDF)
Reranking
- To fix the disadvantage of the bi-encoder approach when documents’ and queries’ representations are computed separately, we can add another reranking stage with cross-encoder as an extra step, before calling the generator model. ^2dc17c
- The idea is to use a powerful, computationally expensive model to score only a subset of your documents, previously retrieved by a more efficient and cheap model. It is not computationally feasible for each query-document pair.
- A typical reranking solution uses open-source Cross-Encoder models from sentence transformers, which take both the question and context as input and return a score from 0 to 1. Though it is also possible to use GPT4 + prompt engineering.gg
- Originally, cross-encoder is a binary classifier where the probability of being a positive class is taken as a similarity score. Now there are also T5-based rerankers, RankGPT, …
- generally bi-encoder is more loose and reranker is more strict
- Search reranking with cross-encoders
- Retrieve & Re-Rank — Sentence Transformers documentation
- Reranker can be
- an embedding model classifying data is relevant or not.
- a cross-encoder model with a nuanced output between 0 and 1
- an LLM-based
- In terms of speed BM25 or TF-IDF is the fastest (but lower accuracy), then goes the cosine similarity-based bi-encoder and, finally, a precomputed cross-encoder classifier is extremely compute-intensive
- For evaluation of reranker models we need hard negatives - examples very similar to relevant chunks, but which should not be ranked high.
- be diligent and creative with properly selecting triplets for reranker training, see also Sampling methods for reference
- Reranker-as-a-Service: Cohere \ Boost Enterprise Search and Retrieval with custom fine-tuning via API possible
- default reranker can often yield worse results, so fine-tuning with custom (synthethic data) is advised
How to select every ranking model for fine tuning
- It’s an iterative process where one cannot just select the perfect model architecture from the beginning. Instead, it’s good to create a framework which will include testing several models and evaluating them against specific constraints such as latency, costing requirements, and performance.
- https://bge-model.com/ I
Full MVP vanilla RAG
- Full MVP vanilla RAG pipeline may look like this (with combine the scores module too)
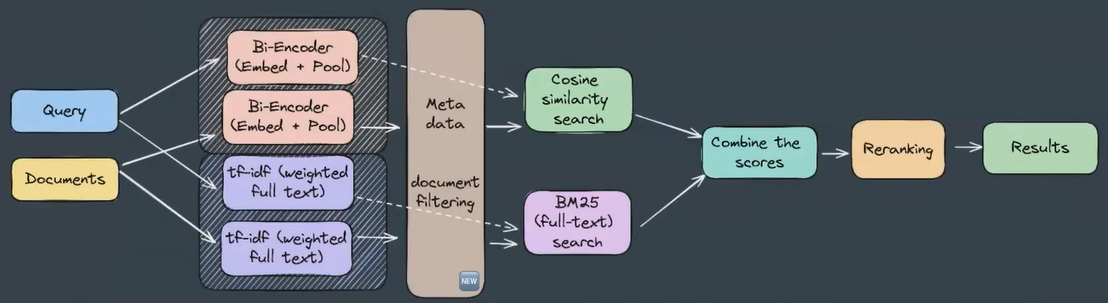
Evaluating information retrieval
Evaluating generation
- Grounding \ faithfulness
- Is the output supported by retrieved chunks?
- ROUGE \ BERTScore overlap vs retrieved chunks
- LLM-as-a-judge Asking whether this claim is supported
- Is the output supported by retrieved chunks?
- Context utilization
- Does the LLM use the retrieved facts effectively?
- Entity or keyword match rate between documents and output
- attention weight alignment in case of using open LLMs
- Does the LLM use the retrieved facts effectively?
- Attribution accuracy
- Can we trace back specific statements in the output to individual chunks?
- Manual or automatic tagging of outputs links to source IDs.
- LLM-as-a-judge: Which document supports this statement?
- Can we trace back specific statements in the output to individual chunks?
- hallucination rate
- Detect invented content
- % of claims unsupported by retrieval.
- Handling irrelevant retrieval
- Can it ignore noisy or unrelated content?
- LLM-as-a-judge: Categorize items and rate how model uses relevant and irrelevant content.
- Faithfulness under distractors.
- Is it robust to misleading or conflicting information?
- Manual adversarial testing with incorrect retrieval.
- Automated contradiction detection.
- Information combination
- Is it able to stitch multiple pieces of evidence into a coherent answer?
- Count the number of unique sources referenced.
Challenges with RAG
- Lost in the Middle effect (not specific to RAG, but rather long context)
- RAG retrieval capabilities are often evaluated using needle in a haystack tasks, but that is not what we usually want in real world tasks (summarization, joining of sub-parts of long documents, etc.) ⇒ knowledge graph may be a good improvement for this
- multi-hop question answering, reasoning-based queries that require connecting information from multiple sources -⇒ -⇒ pre-constructed knowledge graph is potentially a solution, agentic AI workflows
- documents’ encoding failures due to formats, tables or unexpected encoding (e.g. UTF-8 vs Latin-1) silently reduce your knowledge index -⇒ monitor processed data at each step, implement error handling, be careful with off-the-shelf PDF extractors
- Irrelevant documents accumulate and await to be retrieved for a query, ticking time bombs -⇒ careful curation, metadata filtering
- documents can become irrelevant with time: Index staleness, database needs to be always up-to-date -⇒ timestamps metadata filtering
- Privacy or access rights can be compromised when RAG is used by various users
- Database may contain factual or outdated info (sometimes along with the correct info) ⇒ increase data quality checks or improve model robustness, put more weight on more recent documents, filter by date
- Relevant document is missing in top-K retrievals -⇒ improve the embedder or reranker
- Relevant document was chopped during context retrieval -⇒ use LLM with larger context size or improve the mechanism of context retrieval
- Relevant document got into top-K, but the LLM didn’t use that info for output generation ⇒ finetune the model for the contextual data or reduce the noise level in the retrieved context
- LLM output is not following expected format -⇒ finetuning the model, or improve the prompt
- Pooling dilutes long text representation: During the encoding step, each token in the query receives a representation and then there is a pooling step which is typically averaging to provide one vector for all tokens in a query (query-sentence ---> one vector)
- chunking strategy is a hyperparameter and it is not independent from others.
- Arbitrary queries
- Low information value or vague queries (e.g. “health tips”) -⇒ detect through heuristics or classifiers and ask users for clarification
- Off-topic queries ⇒ intent recognition and fallback scenario
- temporal data
- challenging because the model needs to keep track of order of events and consequences
- medical\prescription records, FED speeches, economic reports
- present chunks chronologically, explore the effect of ascending vs descending order
- two-stage approach: let the model first extract and reorganize relevantnt info, then reason about it
- mining reasoning chains from users to create training data
- hallucination -⇒ inline citations
Advanced RAG techniques
Advanced improvements to RAG
Note
RAG intertwines with the general topic of model evaluation, and adjacent to such things as synthetic data generation for RAG evaluation and Challenges with RAG
Chunking
Chunking strategy
Note
- ==chunking strategy== can have a huge impact on RAG performance. ^c77646
- small chunks ⇒ limited context ⇒ incomplete answers
- large chunks ⇒ noise in data ⇒ poor recall
- general, but not-universal advice: use larger chunks for fixed-output queries (e.g. extracting a specific answer\number) and smaller chunks for expanding-output queries (e.g. summarize, list all…).
- By symbols, sentences, semantic meaning, using dedicated model or an LLM call
- semantic chunking by detecting where the change of topic has happened
- Consider inference latency, number of tokens embedding models were trained on
- Overlapping or not?
- Use small chunks on embedding stage and large size during the inference, by appending adjacent chunks before feeding to LLM
- page-size chunks, because we answer the question “on which page can I find this?”
- sub-chanks with links to a parent-chunk with larger context
- parent-child chunking, when search is done on smaller chunks but the context gets filled with, for instance, full page data
- hierarchical chunking gradually zooms into relevant context and improves efficiency of clarifying questions within a multi-turn conversation
- multiple levels based on document metadata, sections, pages, paragraphs and sentences
- Each chunk retains information about its metadata, hierarchical level, parent-child relationship, extracts confidence scores, etc.
- Shuffling context chunks will create randomness in outputs, which is comparable to increasing diversity of the downstream output (as an alternative to hyperparameter tuning using softmax temperature) - e.g. previously purchased items are provided in random order to make recommendation engine output more creative ^447647
- shuffle the order of retrieved sources to prevent position bias
- unless sources are sorted by relevance (the model assumes that the 1st chunk is the most relevant)
- newer models with large context windows are less prone to the Lost in the Middle effect and have improved recall across the whole context window
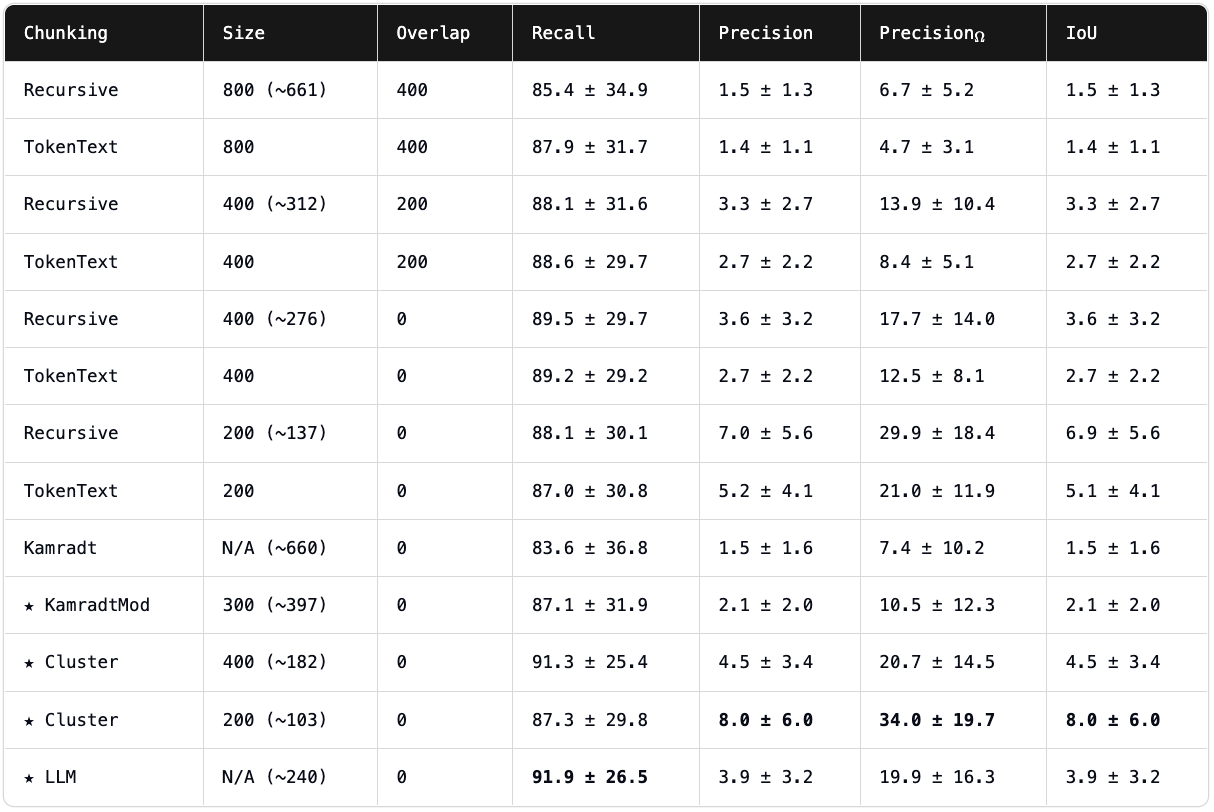
Link to originalChunking rankings from https://research.trychroma.com/evaluating-chunking
Fine-tuning
- Not RAG-specific, but off-the-shelf embedding models can be fine-tuned like any other model. It requires sufficient data, but can prove very useful the more specific is the task at hand.
- handcraft hard positive and hard negative examples
- fine-tuning to make models output citations\ref to avoid hallucination in critical domains ^95a6c6
- create source\chunk ids and use them as tags in metadata, possibly include first\last 3 words. Then fine-tuning the model
- validate the existence of citations, possibly validate semantic relevance of the content
- Start with small batches, measure performance, and increase data volume until you reach your desired accuracy level.
Better search
- In addition, to dense embedding models, historically, there are also sparse representation methods. These can and should be used in addition to vector search, resulting in hybrid search ^f44082
- Using hybrid search (at least full-text + vector search) is standard to RAG, but it requires combining several scores into one ^6fd281
- use weighted average
- take several top-results from each search module
- use Reciprocal Rank Fusion, mean average precision, NDCG, etc.
- example: Faiss and kNN use our embedding and BM25TF-IDF use their own representation
- metadata filtering reduces the search space, hence, improves retrieval and reduces computational burden, prevents index staleness
- Dates. freshness\timestamps, source authority (for health datasets), business-relevant tags
- categories: use named entity recognition models: GliNER
- if there is no metadata, one can ask LLM to generate it,
- less beneficial if your index is small or query types are limited
- create search tools specialized for your use-cases, rather than search for data types. The question is not whether I am searching for semantic or structured data?, but which tool would be the best to use for this specific search? ^c819e0
- Generic document search that searches everything, Contact search for finding people, Request for Information search that takes specific RFI codes.
- Evaluate the tool selection capability separately
- Make the model write a plan of all the tools it might want to use for a given query. Possibly present the plan for users approval, creates valuable training data based on acceptance rates.
- The naming of tools significantly impacts how models use them. Naming it grep or else can affect the efficiency.
- separate indices for document categories
- extract specific data structures for each type
- see here
- formatting ^9d73c5
- Does Prompt Formatting Have Any Impact on LLM Performance?
- check which format (markdown, json, xml) works best for your application. there are also discussions about token-efficiency
- spaces between tokens in markdown tables (like ”| data |” instead of “|data|”) affects how the model processes the information.
- The Impact of Document Formats on Embedding Performance and RAG Effectiveness in Tax Law Application
- Synonyms and taxonomic similarity
- Generating more user queries with synonyms may not be effective, because synonyms do not fit the context
- If there is a taxonomy list, like for instance in ecommerce, one can create a prompt to classify a user query to one of those taxonomy entries, e.g.
furniture>Baby furniture>Crib&Toddler bed accessoriesand then search among hyponyms (children, more specific concepts), hypernyms (parents, more general groups) or siblings (similar to the selected category).Reranker
- reranker
- see Re-ranking
- minimize using of manual boosting (e.g. boost recent content or specific keywords)
Other
- See also Inference Scaling for Long-Context Retrieval Augmented Generation
- One can generate summary of documents (or questions to each chunk\document) and embed that info too
- query expansion and enhancement to make queries look more alike to documents in the database
- Another LLM-call-module can be added to rewrite and expand the initial user query by adding synonyms, rephrasing, complementing with initial LLM output (without RAG context), etc.
- if costs are not an issue, multiple copies of the same query can be processed for higher confidence (e.g. intent recognition)
- implement intent recognition and reroute simple queries to simple handlers, no need for a full RAG pipeline, if something can be answered with an SQL or metadata filtering
- multi-agent vs single-agent systems
- communication overhead if agents are NOT read-only, need to align who modifies what
- if all read-only, for instance, in search of personality info - one may search professional sources, one about personal life, another smth else
- benefit of multi-agents - token efficiency, Especially if there are more tokens than one agent can consume in the context
- The performance just increases with the amount of tokens each sub-agent is able to consume. If you have 10 sub-agents, you can use more tokens, and your research quality is better
Extra
Link to original
- AutoML tool for RAG - auto-configuring your RAG
- Contextual Retrieval \ Anthropic
- Query Classification / Routing - save resources by pre-defining when the query doesn’t need external context and can be answered directly or using chat history.
- Multi-modal RAG, in case your queries need access to images, tables, video, etc. Then you need a multi-modal embedding model too.
- Self-RAG, Iterative RAG
- Hierarchical Index Retrieval - first search for a relevant book, then chapter, etc.
- Graph-RAG
- Chain-of-Note
- Contextual Document Embeddings
Other topics
Inference Scaling for Long-Context Retrieval Augmented Generation
Resources
- paper review Seven Failure Points When Engineering a Retrieval Augmented Generation System - YouTube or Семь точек отказа RAG систем | Дмитрий Колодезев
- Back to Basics for RAG w/ Jo Bergum - YouTube
- Mastering RAG: How to Select A Reranking Model - Galileo
- ==Systematically improving RAG applications – Parlance==
- Подбор гиперпараметров RAG-системы с помощью Optuna / Хабр
- A Beginner-friendly and Comprehensive Deep Dive on Vector Databases: ArchiveBox from dailydoseofds
- RAG From Scratch: Part 1 (Overview) - YouTube
- Local Retrieval Augmented Generation (RAG) from Scratch (step by step tutorial) - YouTube: 5 hours step by step hands-on tutorial
- Retrieval-Augmented Generation for Large Language Models: A Survey
- [awesome RAG](https://github.com/Poll-The-People/awesome-rag
Data Talks Club
DTC - LLM Zomcamp
RAG in Action: Next-Level Retrieval Augmented Generation - Leonard Püttmann - YouTube
Implement a Search Engine - Alexey Grigorev - YouTube
deeplearning.ai
DLAI - Building and Evaluating Advanced RAG
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"