transformer
scroll ↓ to Resources
Contents
- Notes
- [[#Notes#Important components of transformer architecture|Important components of transformer architecture]]
- [[#Notes#Memory and optimization|Memory and optimization]]
- Encoder
- Decoder
- Best practices - model training
- Resources
Notes
- A transformer may consist of encoder and decoder parts, or only one of them.
- Encoder
- encoder is meant to transform input to some good quality representation. The output from the encoder is a series of embedding vectors representing the entire input sequence.
- encoder-only is enough if: ^e8ddc3
- you need to make a decision regarding the whole input (classification). Just add softmax to the end of encoder and you are good to go
- you need to create structured output with input’s structure
- Decoder
- takes encoder-generated vectors and produces structured output in target domain not bound to inputs’ structure
- output distribution is close to input distribution (e.g. generating inputs’ text continuation in the same language)
- both encoder and decoder are needed when output distribution is not the same as inputs distribution
- Encoder
Important components of transformer architecture
- multi-head attention
- makes whole input “look at itself”
- the decoder layers employ two types of attention mechanisms: masked self-attention and encoder-decoder cross-attention.
- Masked self-attention ensures that each position can only attend to earlier positions in the output sequence, preserving the auto-regressive property and preventing the decoder access to future tokens in the output sequence.
- The encoder-decoder cross-attention mechanism allows the decoder to focus on relevant parts of the input sequence, utilizing the contextual embeddings generated by the encoder.
- skip connection
- improves gradient flow
- positional encoding
- allows the transformer to preserve info about order of input vectors
- modern models like paper review - Llama 3 Herd of Models use advanced rotary embeddings, but the purpose is the same - to allow word order and word distance affect the attention
- layer normalization
- quality of gradients, smoothes loss surface
- feed-forward layer
- Transformer Feed-Forward Layers Are Key-Value Memories
- typically consists of two linear transformations with a non-linear activation function, such as ReLU or GELU, in between
- later layers are responsible for catching semantics of the text, whereas first layers primarily look for shallow features (e.g. specific words ar specific locations)
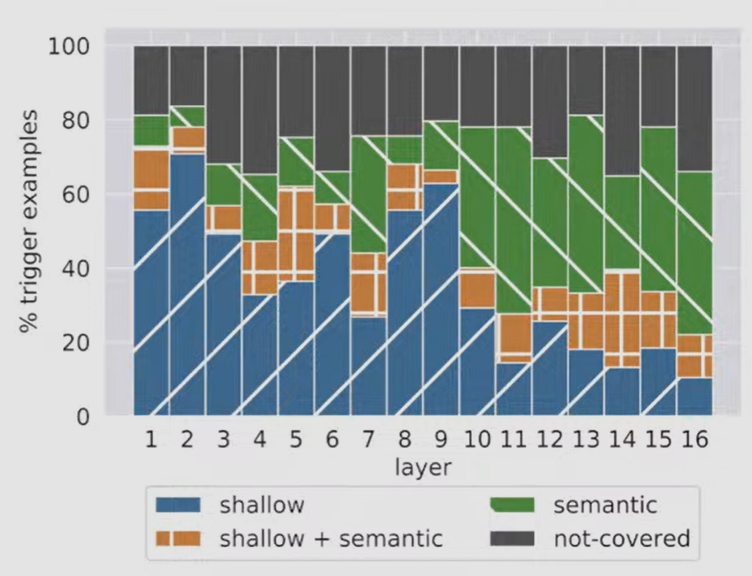
- this architecture allows many useful modifications with minimal changes to the number of parameters.
Memory and optimization
- one of the issues with transformer is that attention memory usage grows quadratically with input size
- flash attention method allows more efficient usage of GPU memory and higher allocation for computations (sublinear time instead of quadratic). This method requires more computations to be done, but instead reduces the memory bottleneck.
- if each parameter takes 32 bits, Then, during the model training, each parameter will require 16 times that space: 4 bytes for the parameter itself, 4 bytes for its gradient and 8 bytes optimizer state - 16 bytes in total for each parameter
- 70B 16b models require around 1.5Tb memory to store a checkpoint, not even for training yet
- techniques like mixed precision and quantization help reducing this ~ 10 times
Encoder
encoder architecture from excalidraw encoder layer

- original idea was that the outputs of encoder will serve as keys and values inputs for decoder layers, which will get queries from outside.
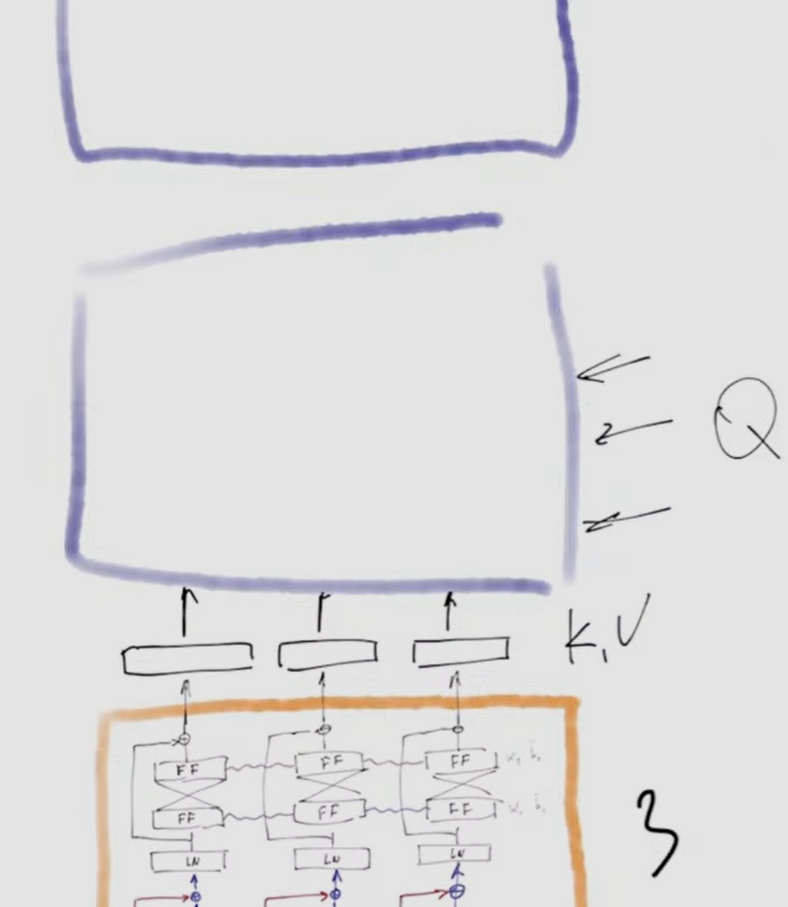
- On practice there are many neural network architecture without decoder, like BERT. For instance, classification tasks can be solved using only encoder. See Notes.
- it is possible to add another trainable input vector called CLEEEES token if the task is to classify the whole text, not individual input vectors.
- The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
Decoder
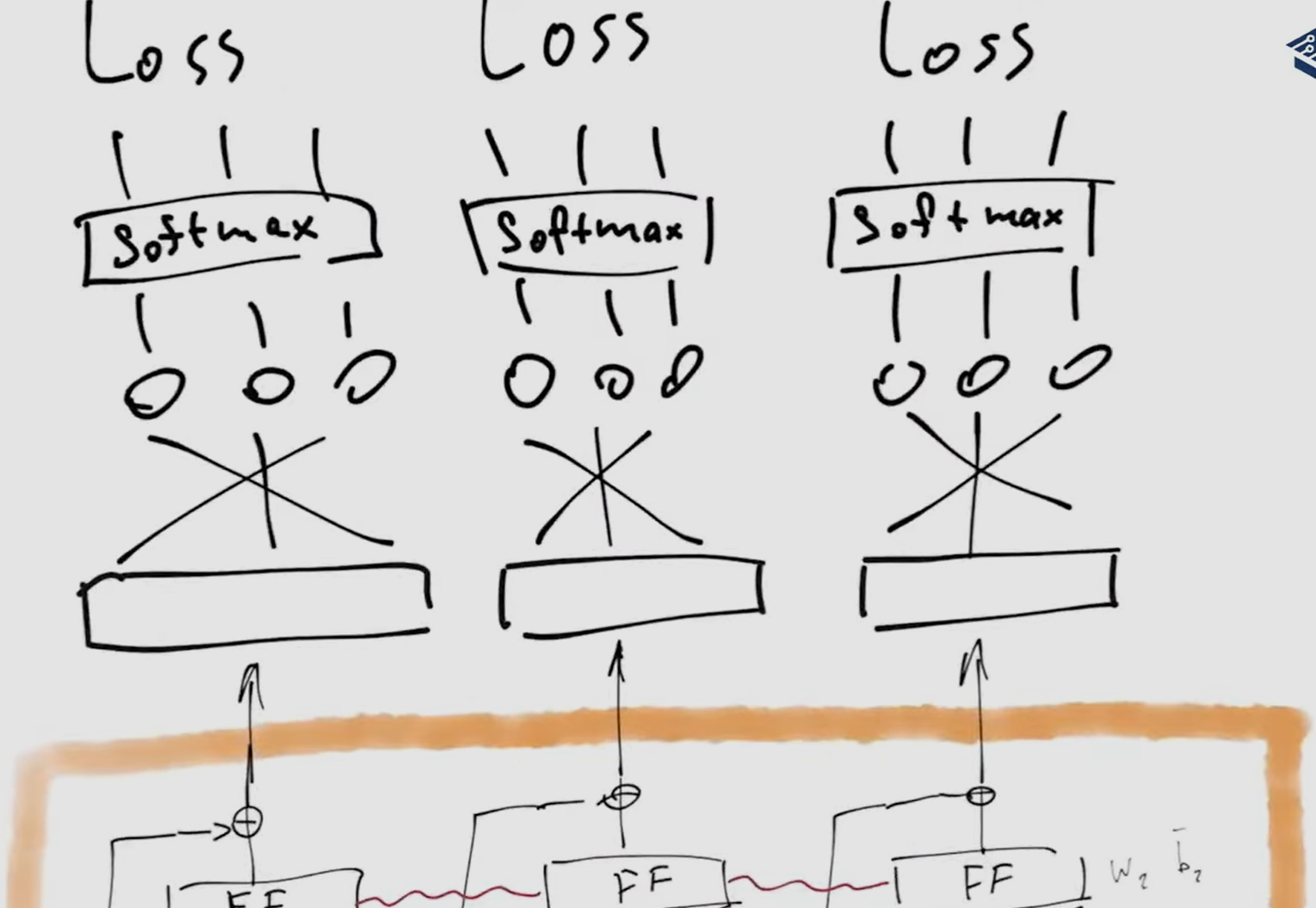
decoder architecture from excalidraw decoder layer

original encoder-decoder architecture from the attention-paper

- if it is a decoder-only architecture, the second multi-head attention is removed
- during training, if we want it to output “Never gonna let you down”, but it starts with any other wrong token (e.g. “I”), we still supply the correct \expected token “Never” to the next iteration, as if it generated correctly. this is called teaching forcing

- multi-head attention
- we can train the decoder in one pass, but during the inference we run it many times, first with the token start, than start and it’s first output token, than again with start and 2 output tokens, … until we receive end-of-sequence token.
- taking many tokens as input is easier than generating many tokens ⇒ asking LLM if the given answer is correct is faster \ cheaper for inference than asking it to produce the correct answer
Best practices - model training
- model training
- learning rate warm-up is used in all modern architectures, followed by either linear decay or cosine annealing
- weights initialization
- bias 0
- Xavier
- all GPT models use GELU activation instead of ReLU
- post GPT-2 models moved layer normalization before multi-head attention and feed-forward layer in opposite to classic layout: multi-head attention⇒addition⇒layer normalization. Research shows that decreases gradients, models train faster
- optimizer Adam or its modifications
Resources
- Stanford CS25: V4 I Overview of Transformers - YouTube
- Архитектура Transformer. Лекция 21. - YouTube
- Transformer Explainer: LLM Transformer Model Visually Explained
- The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
- The Annotated Transformer annotated jupyter-notebook
- Transformers from scratch | peterbloem.nl
- LLM Foundations (LLM Bootcamp) - YouTube
- GitHub - sgrvinod/a-PyTorch-Tutorial-to-Transformers: Attention Is All You Need | a PyTorch Tutorial to Transformers
Links to this File
table file.tags from [[]] and !outgoing([[]]) AND -"Changelog"