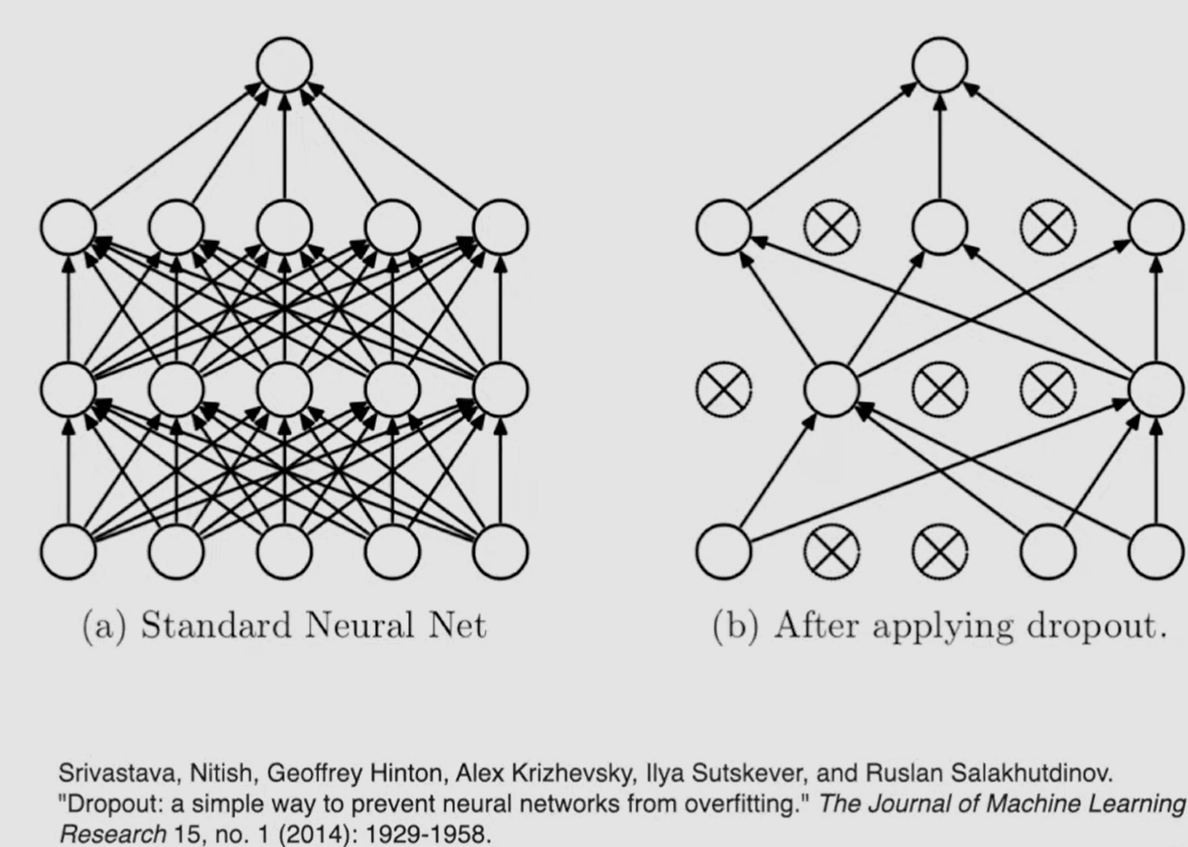
more generally, dropout can refer to dropping out not only individual neurons (in other words feature dropout), but als structure dropout (skipping whole layers), or data dropout (e.g. skipping words from input vector in NLP tasks)
Dropout modifications:
DropConnect when not neurons, but connections are dropped
Curriculum dropout: gradually switch on dropout to make learning easier at first (because neural net can’t do much yet) and harder later, because the network is more capable
Augmented dropout: separate dropout hyperparameters for forward and backward passes
dropout is applied only during the training stage
there are minor modifications that have to be made during inference, where ==we again switch ALL neurons and discard dropout layer==
activation value has to be multiplied by p to account for dispersion mismatch between training and inference stages
another approach inverted dropout accounts for that already during training, then nothing has to be changed during inference: during training stage, knowing that part of neurons will be switched off, we scale the rest of them to keep the distribution same
in practice, input layers dropout probability is usually close to 1, hidden layers ~ 0.5 and it can't be used on last\output layers
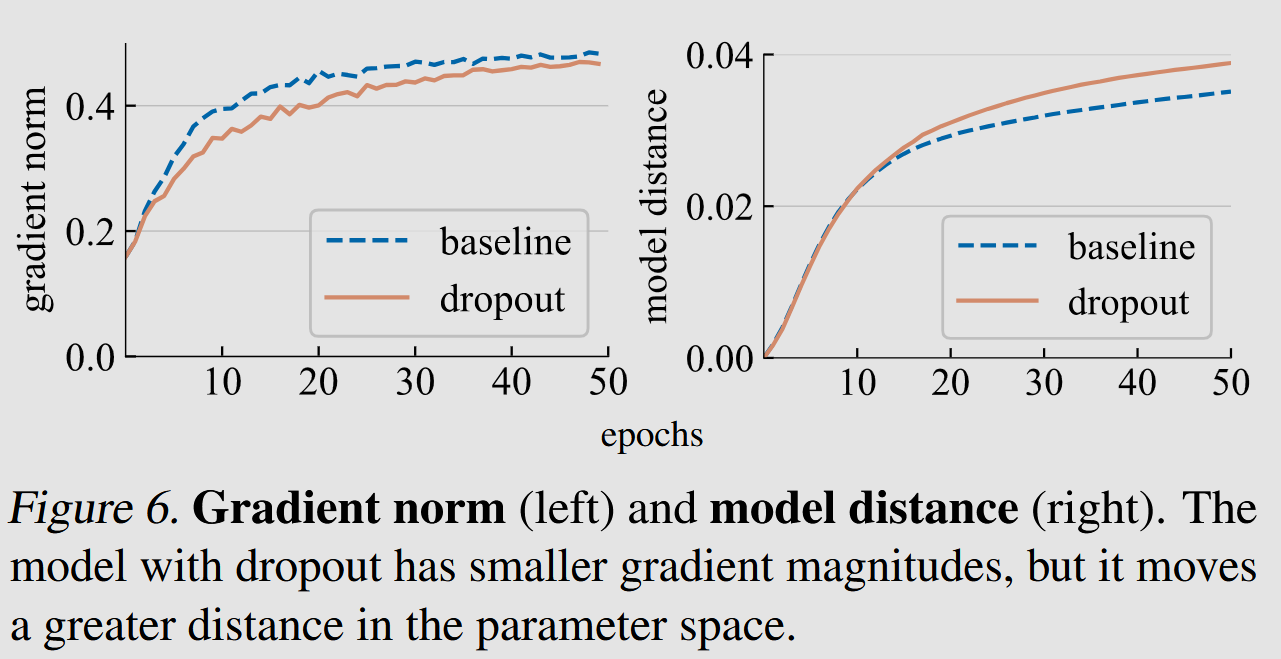
Gradient norm shows how big are the gradient descent steps at each update iteration. Left plot shows that with dropout the steps are smaller, than without dropout (for fixed learning rate)
Model distance is the distance in the parameter space from initialization until the current moment in training process. That is effective distance. The plot on the right says that dropout increases the distance made.
Concluding:
dropout ensures smaller steps in consistent direction, resulting in better overall training efficiency
dropout helps if your model is too simple
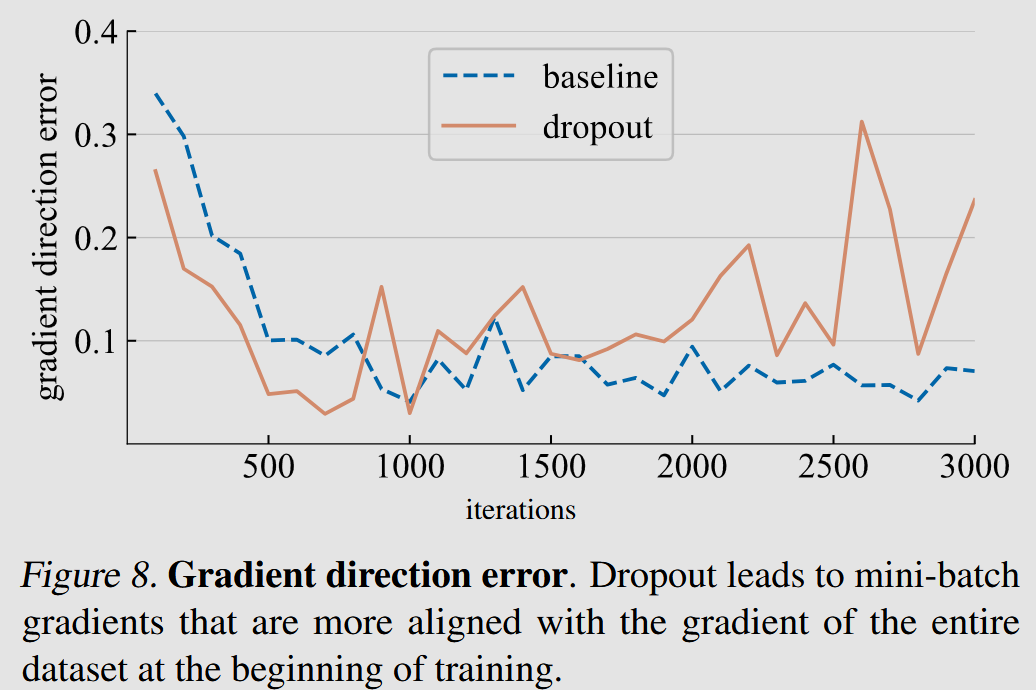
Gradient direction error is the difference between the mini-batch computed gradient and the gradient computed using the whole dataset
the plot shows that, if dropout is used, this error is smaller at early training iterations
early dropout decreases underfitting, late dropout decreases overfitting
authors suggest to switch drop-out on and off during the training based on whether your model is over- or under-fitting
Resources
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"