Not Another Imputation Method
scroll ↓ to Resources
Contents
- Note
- Architecture
- [[#Architecture#Feature embedding|Feature embedding]]
- [[#Architecture#Masked self-attention|Masked self-attention]]
- [[#Architecture#Transformer-encoder|Transformer-encoder]]
- [[#Transformer-encoder#Encoder|Encoder]]
- [[#Transformer-encoder#Regularization|Regularization]]
- Resources
Note
- encoder-only architecture with multi-headed attention that skips masked (missing) values
- does not explicitly impute the data as a preprocessing step, but implicitly handles missing values for the purpose of classification task.
- missing features are embedded as zero vectors (padding index)
- Masked attention ensures these missing features do not influence the outcome
- the encoder output is based only on non-missing data
- classification is made using this partial information without ever filling in the missing values
Architecture
Feature embedding
- First, that is feature embedding, where each categorical numerical feature is encoded using trainable lookup tables. For categorical values, these lookup tables have exactly the number of rows equal to how many possible categories are for this feature. So the lookup table is feature specific. For numerical values, table is not feature specific and only has two roles to encode existing value and missing value. These embedding are then computed using the formulas
- categorical value embedding = feature bias (trainable, not category-, but feature-specific) + look-up-table row corresponding to that category (the table is trainable and feature-specific for the reason of different categories per feature)
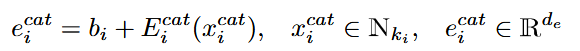
- numerical value embedding = feature bias (trainable) + feature value x one of the two rows (missing\existing) in the feature-specific look-up-table
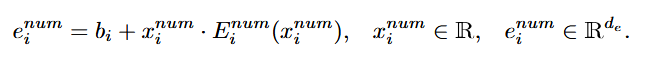
- categorical value embedding = feature bias (trainable, not category-, but feature-specific) + look-up-table row corresponding to that category (the table is trainable and feature-specific for the reason of different categories per feature)
- All acquired embedded representations are concatenated together into a matrix , with - the number of features and is an embedding dimension. The matrix is passed into transformer encoder.
Masked self-attention
- The traditional transformer calculates the query, key and value matrices through linear transformation of the input matrix , mapping the embedding into a smaller space And the number of heads .
- Normally, thenmasked self-attention is applied for excluding future tokens (causal masking) or last (padding) tokens.
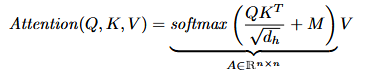
with being an attention matrix and - a mask. - Traditional approach (masking columns corresponding to missing features) to design does not completely exclude the effect of missing values, because these can appear as keys, values, but also queries.
- Therefore, is applied twice:
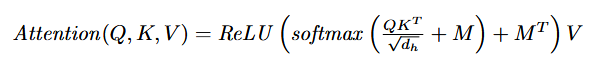
- added to the attention scores matrix masking columns corresponding to missing features).
- added as the transpose MTMT (masking rows corresponding to missing features)
Transformer-encoder
Encoder
- encoder layers - 6
- embedding dimension - 6
- attention heads - 3
- feed-forward layer size - 1000 neurons
- cross-entropy loss,
Regularization
Resources
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"