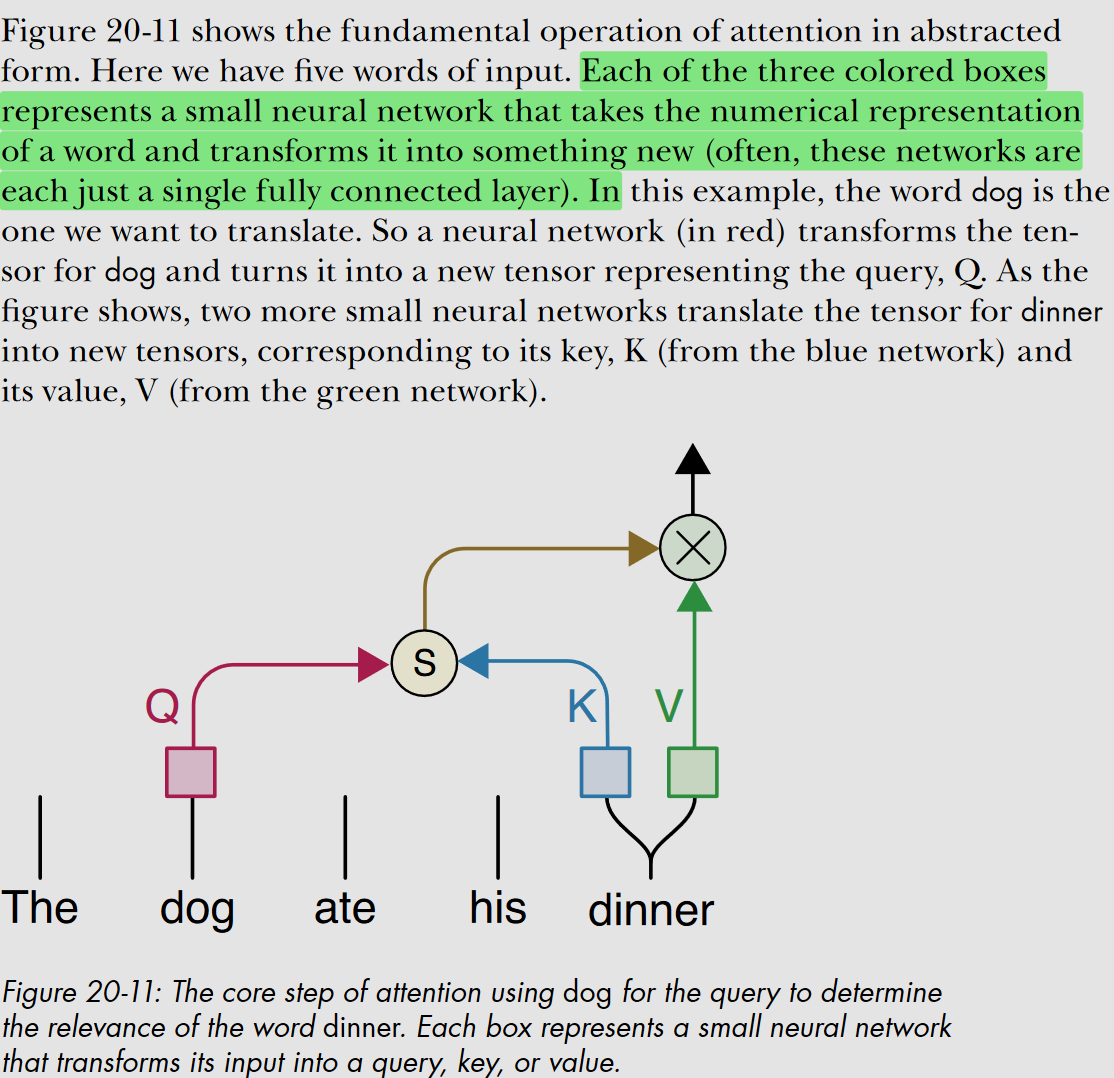
attention
scroll ↓ to Resources
paint analogy

Notes
- “attention” is a mechanism that enables the model to focus on relevant parts of the input sequence while generating the output.
- key insight: For a given token in the output sequence, only one or a few tokens in the input sequence are most important.
- In short, determining relationships between different words and phrases in sentences is achieved thorough these steps:
- Create queries (Q), keys (K) and values (V) vectors
- Calculate scores showing how much each word should attend to other words - by taking the dot-product of Q (each one) word with K vectors of all other words in the sequence.
- Normalized the scores, apply softmax to the scores to obtain attention weights.
- Multiply each V by its attention weight, sum up the results to get a context-aware representation for that word, whose K vector we used in the dot-product
- memory usage of multi-head attention is N2, where N is the number of input vectors, because the attention matrix will be
scaled dot-product attention
- Given that the attention function is a mapping of a query Q and a set of key-value K:V pairs to an output, For an in-depth explanation, it is good to start with a simple lookup table as an attention block and see which modifications are needed.
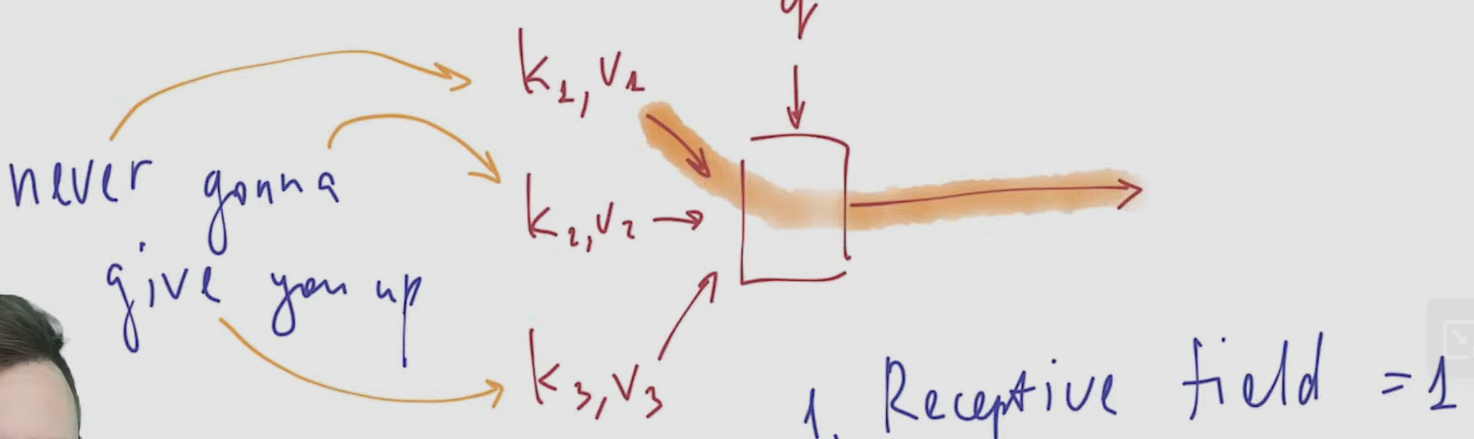
look-up table as a (potential) simplistic block of transformer architecture
NOTE
- key-value pairs K:V
- result R is such V_i for which Q=K_i: indicative function is in the basis of the block
- K and V are some vectors calculated from our neural network inputs or their parts like collection of pixels (in case of images) or selection of tokens (for NLP)
- request Q
- ==receptive field=1 ⇒ deep learning doesn’t work==
- for deep learning we want to train the block
- we can train V values here
- we can’t train K and Q, because derivatives of the look-up table function (indicative function) is 0 by these variables
- ==no learning for Q and K==
- we also need this block to be receptive to small changes in input ⇒ then the gradient flows too strict mechanism, not flexible
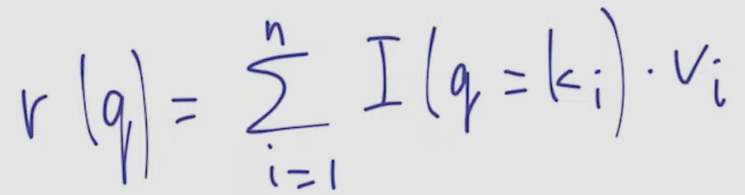
- after understanding the pitfalls, we upgrade the basic look-up table to the scaled dot-product attention
modifying look-up table to be better suited for training ⇒ scaled dot-product attention
NOTE
- let’s generalize indicative function to delta(i) - remember the paint analogy
- ==this is basically the attention mechanism: weighted vectors V==:
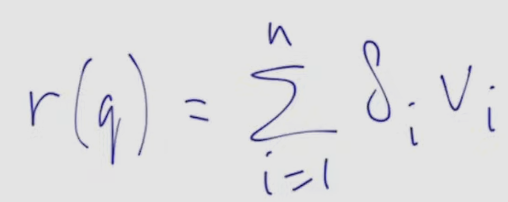
- sum of all , all
- in order to train Q and K, these need to change smoothly and their derivative not equal to 0
- instead of “if Q equals K_i, output V_i” lets use the logic “if Q is similar to V_i, output something similar to V_i”. the smaller the difference, the larger weight delta
- comparisons are made in the vector space by means of scalar multiplication
- after comparing all K to Q we get a vector of weighted deltas
- ==softmax satisfies all of our requirements==: sum of components is 1, each one is >=0, derivative exist and non 0, …
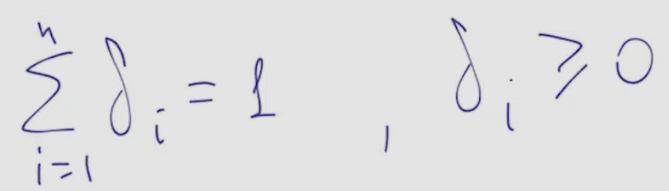
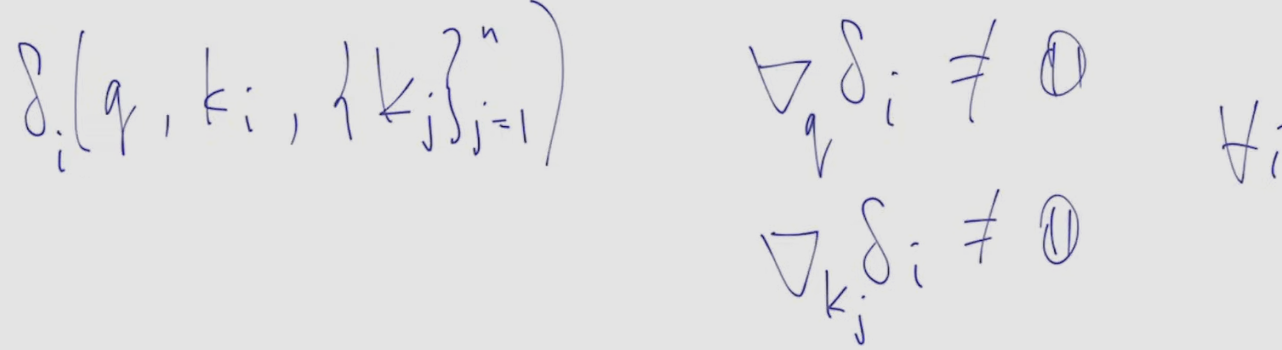
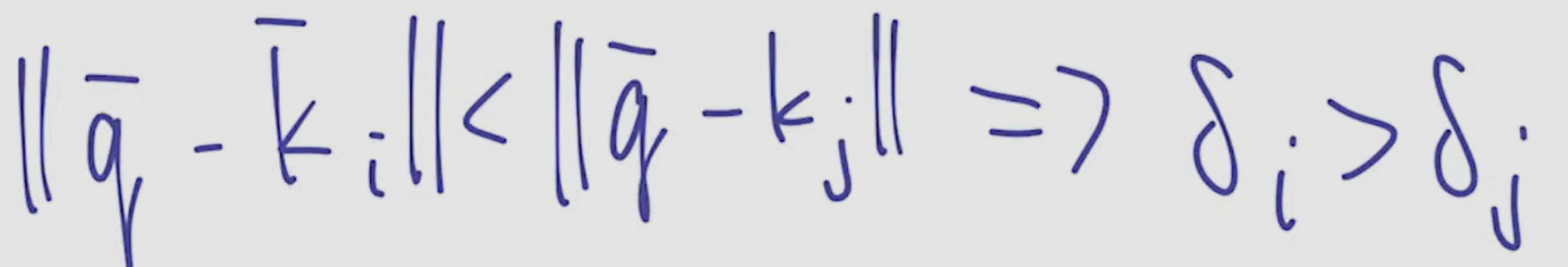
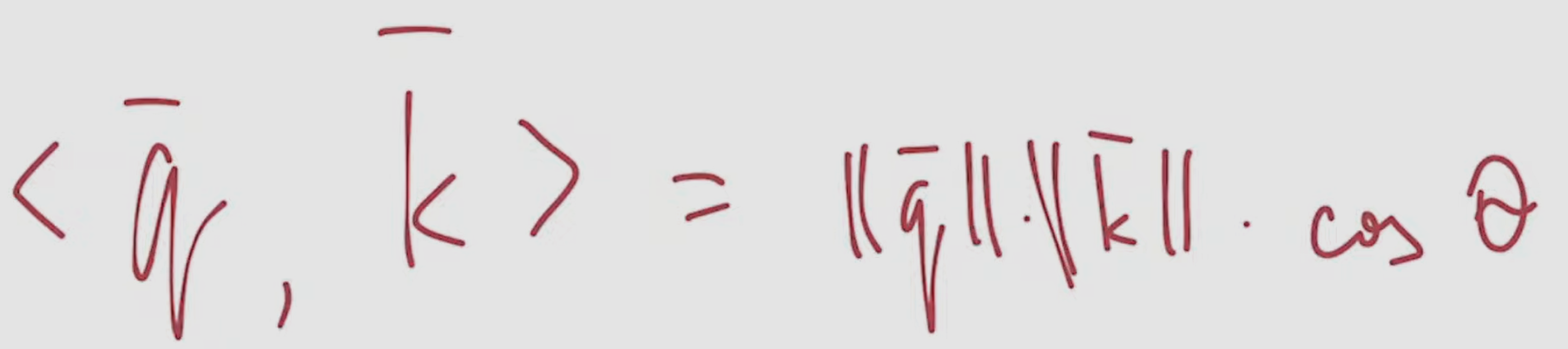
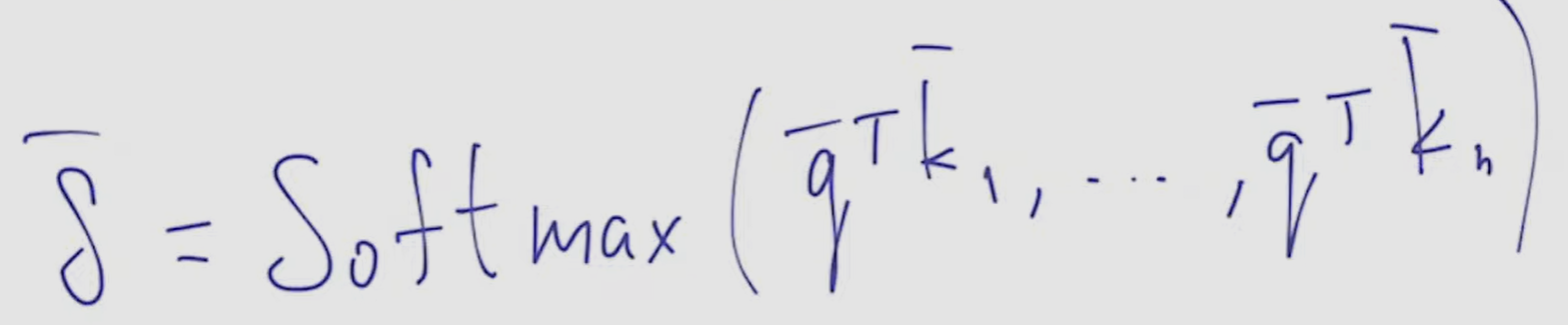
- finally, scaled dot-product attention is sum of V vectors scaled by delta vector, which is softmax taken from all scalar multiplication between vector representations q and k, divided by d (dimensionality of representations, proportional to dispersion)
- the above is valid for ==one query q==, but can be expanded for multiple queries by packing Q, K and V into matrices:
-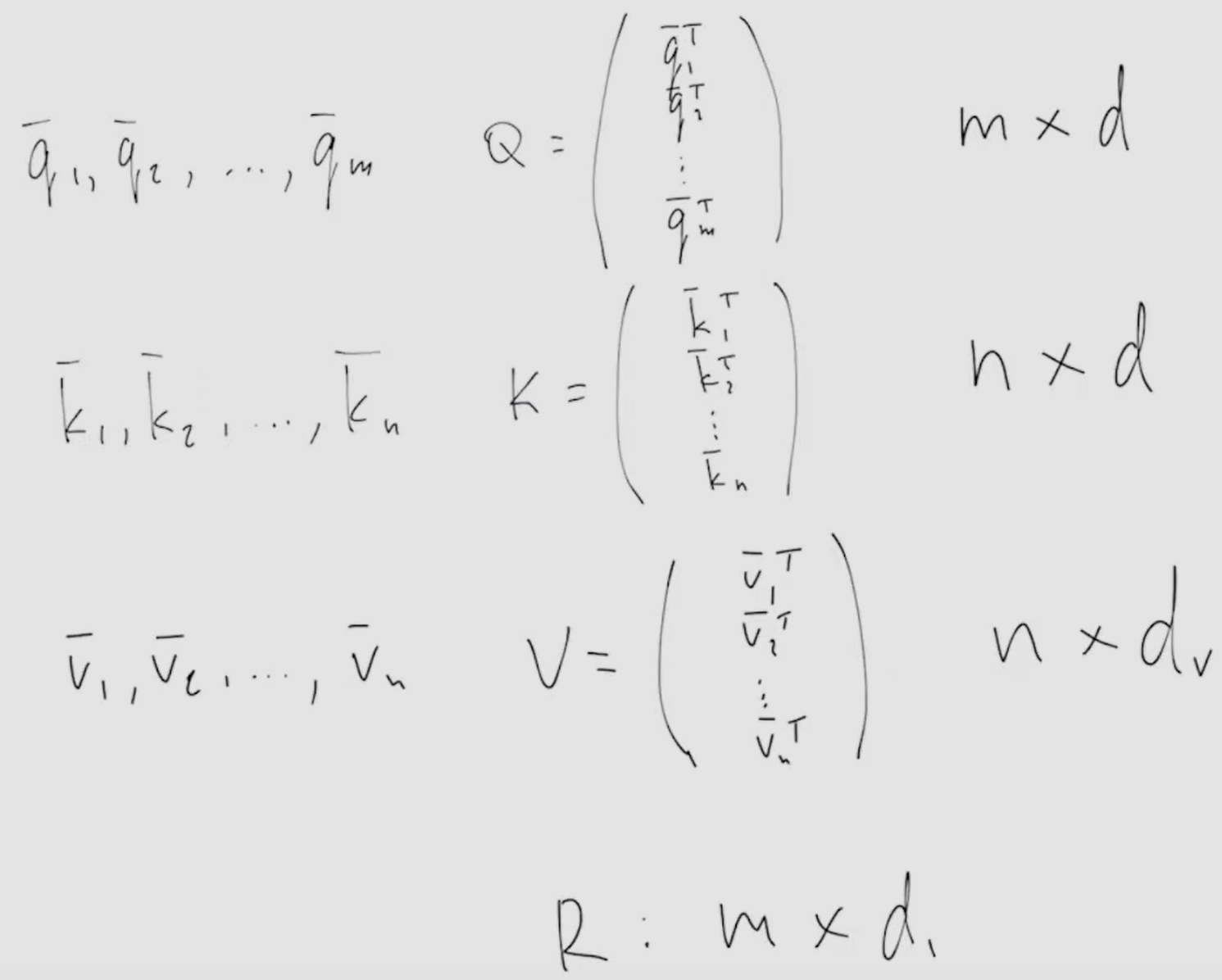
- where all d are the same, m and n are often the same - Summing up, scaled dot-product attention (SPDA):
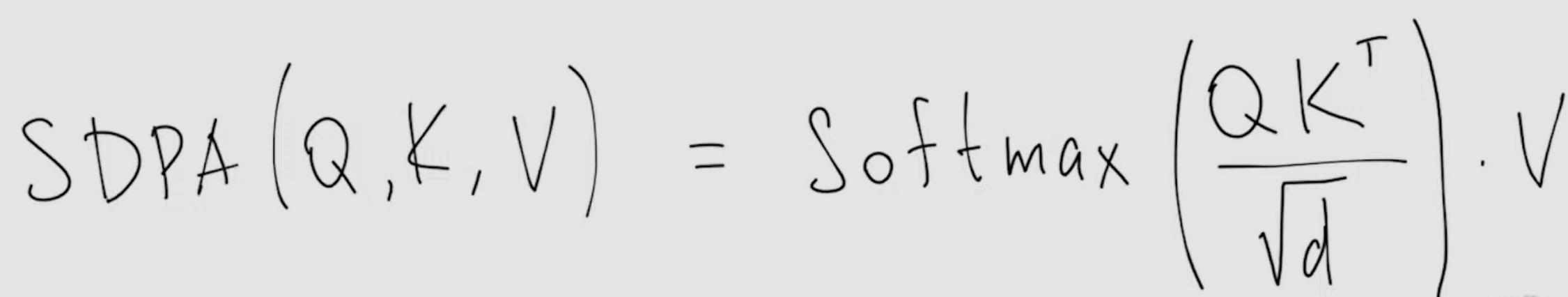 with row-wise softmax
with row-wise softmax
- the SDPA block doesn't contain trainable parameters, but it may let (or not let) through non-zero gradients
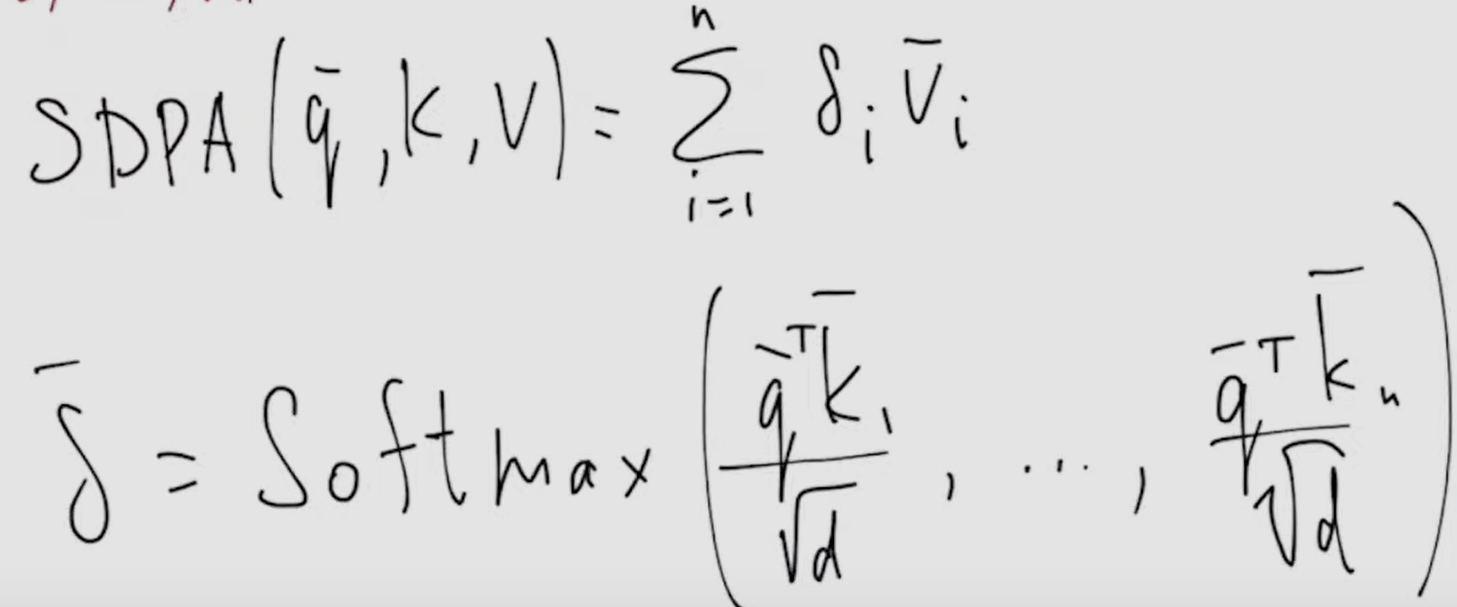
self-attention
- self-attention is a special case of attention where Q, K and V are the same.
- this doesn’t matter as they are modify by different trainable weight matrices Wq, Wk and Wv (see multi-head attention)
- q_i is always the most similar to k_i
- another variation Q/KV Attention uses one source for the queries and another for the keys and values.
Multi-head attention
- scaled dot-product attention has limitations:
- no trainable parameters
- inflexible: it measures similarity based on one fixed (derived during training) criterium, bit there are many ways of making as similarity value for 2 images or sentences. there is no one best answer. we want to have similarity context
- scalar multiplication measure similarity of two vectors, but not two concepts, depicted by vectors. Imagine, the case when Q and K come from different sets \ distributions - e.g. imagesand text. We would want an adapter to transform given Qand K into a new space where these can be better compared.
- how to make it trainable? multiply Q and K by matrices of trainable weights W, potentially also changing the dimensionality
- how to make it flexible
- We can score vectors along multiple criteria by simply running multiple independent attention networks simultaneously. Each network is called a head.
- By initializing each head independently (that is multiplying by several trainable weight matrices), we hope that during training, each head will learn to compare the inputs according to criteria that are simultaneously useful and different from those used by the other layers. If we want, we can add additional processing to explicitly encourage different heads to attend to different aspects of the inputs.
- resulting dimensionalities and output R of multi-head attention
-
-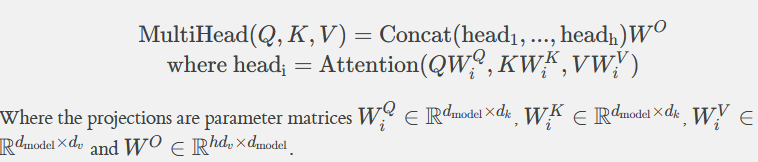
- ==when we change the number of heads h, the number of parameters stays the same==, As long as the input dimension stays constant. This allows tweaking a number of heads and observing which impact does it have on the results of the model.
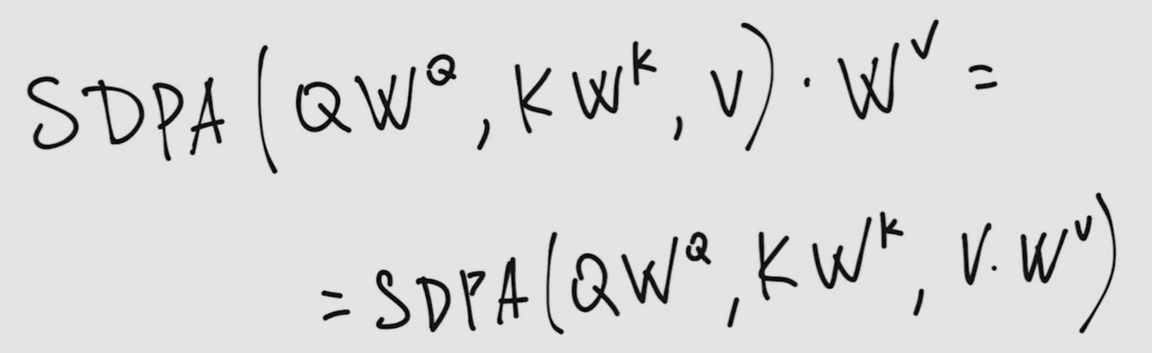
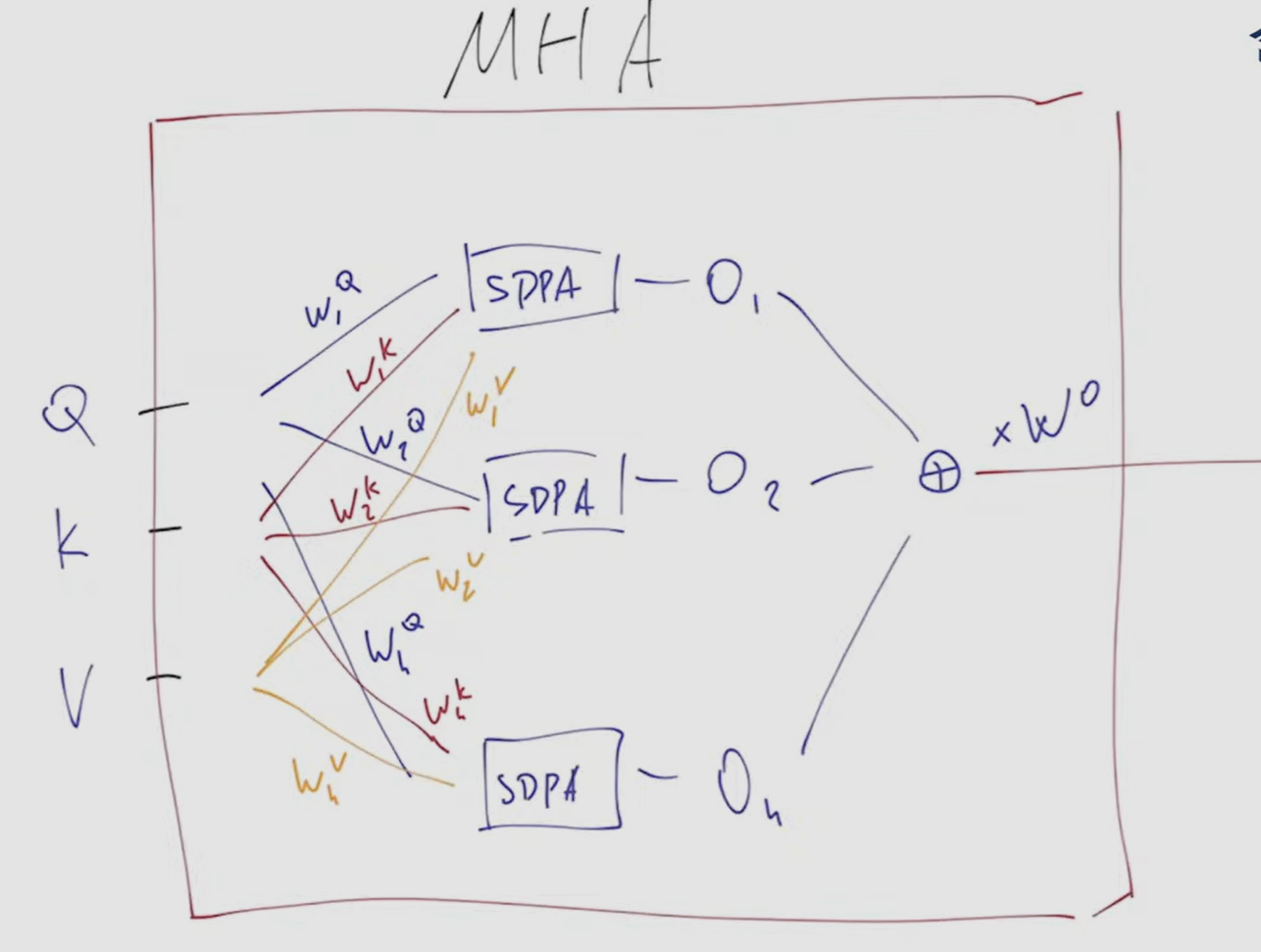
Masked multi-head attention
- done by adding a matrix to the attention matrix before performing the softmax
- this is a powerful method to fully control receptive field of the multi-head attention block, allowing it to see only what we want
- normally, applied to:
- prevent the transformer from seeing the future tokens we expect it to output on each stage (causal masking) - upper-triangular mask with in the upper part to zero their contribution
- allow variable length input outputs during inference - mask out the last (padded tokens)
- but there are other useful applications
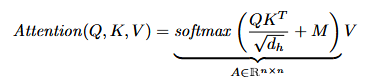
Grouped Query Attention
Resources
- Механизмы внимания в Transformer - YouTube
- Multi-head Attention. Лекция 19. - YouTube
- Attention Is All You Need
- The Annotated Transformer annotated jupyter-notebook
- Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
- Seq2seq and Attention
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"