quantization
scroll ↓ to Resources
Note
- Quantization is the process of decreasing the numerical precision in which weights and activations are stored, transferred and operated upon. The default representation of weights and activations is usually 32 bits floating numbers, with quantization we can drop the precision to 8 or even 4 bit integers, effectively “scaling down” the granularity and mapping a larger original range of values to a smaller set of discreet levels.
- In the figure, the original float7 (purple dots) are mapped to the closest float5 value (green dots) after quantization resulting in lower granularity. This approximation process reduces the number of unique values the model uses, compressing the model while retaining a reasonable level of accuracy.
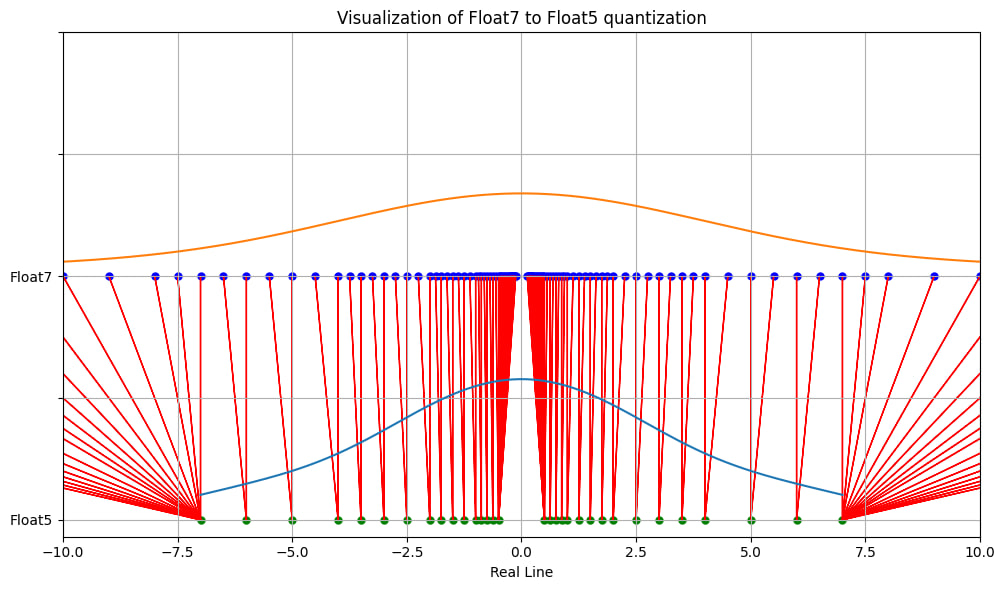
- In cases where quantization might introduce a quality regression, that regression can be small compared to the performance gain, therefore allowing for an effective quality vs latency/throughput tradeoff.
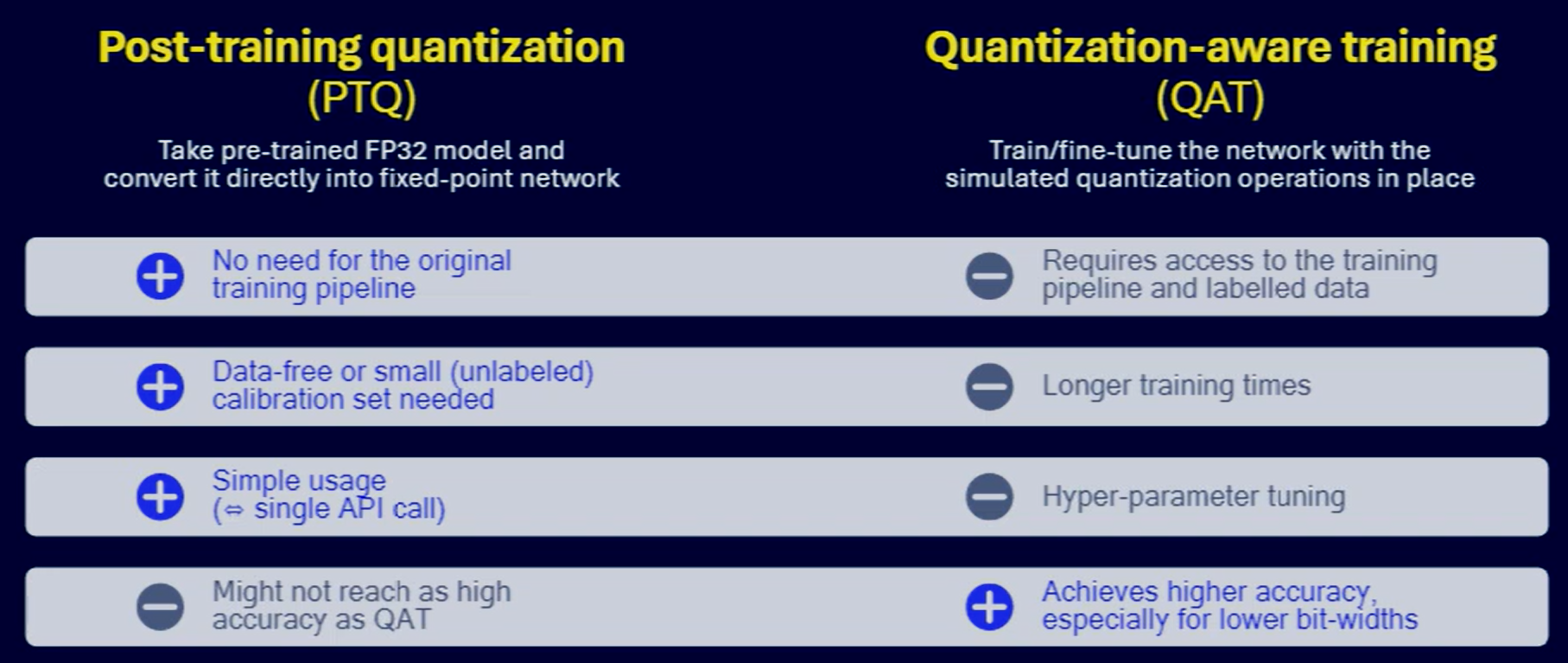
- can be either applied as an inference-only operation (Post-training quantization (PTQ)), or it can be incorporated into the training - referred to as Quantization-aware training (QAT).
- QAT is generally considered to be a more resilient approach as the model is able to recover some of the quantisation-related quality losses during training
- For the best cost-quality trade-offs, one can tweak quantization strategy by selecting different precisions for weights and activations, and also the granularity in which the quantization is applied to tensors, such as channel or group-wise.
Activation-aware Weights Quantization (AWQ)
Post-training quantization (PTQ)
Quantization-aware training (QAT)
Resources
- Webinar: “Quantization: unlocking scalability for LLMs” - YouTube
- Егор Швецов | Model compression -Introduction intro Quantization - YouTube
- Quantization
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"