Since the onset of RAG the number of internal projects for building a corporate chatbot (or more formally, AI assistant) is uncontrolled. What I have seen, didn’t look like anything remotely standardized yet. Also, expectation management is still an big-big issue between internal stakeholders and engineering teams.
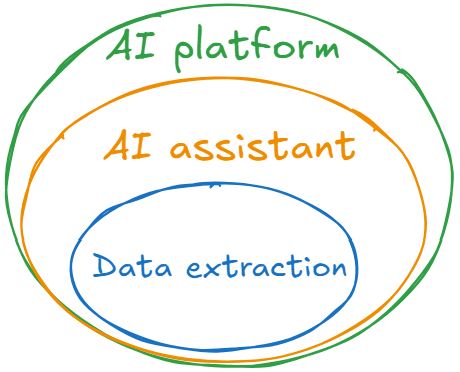
Although, there is going to be a lot about RAG here, but, in practice, no one asks for a RAG. A team lead from Compliance or Legal won’t reach out to AI engineering manager saying “Could you build us a RAG, please?“. They ask to automate business processes of answering questions. Without AI, such a process requires: 1) finding an expert 2) locating relevant data 3) extracting information 4) processing it and 5) synthetizing an answer. Depending on which parts are automated, there are three main project types - Data extraction, AI assistant and AI platform. More often than not, AI assistants encapsulate Data extraction and AI platforms include both of them and more.
Data extraction projects - are the simplest, easiest to implement and (what is crucial in the context of this post) evaluate (come back to that later). The goal is to extract information from sources such as PDFs, graphs, and tables into some structured form, ready to be passed further on along automated pipeline. That is information is known to be stored in a given document and needs to be extracted as is. Sometimes it may not even require an LLM to do what is requested. AI assistant \ AI search - the most popular and demanded type of enterprise LLM projects as it adds question answering capability on top of data extraction + information availability is not 100% guaranteed and\or its format and location is unknown. AI platforms projects is when a stakeholder wants a unified solution for multiple internal business processes. If you work in a big-big corporation you may already have experience with internal co-pilot built-in across multiple services.
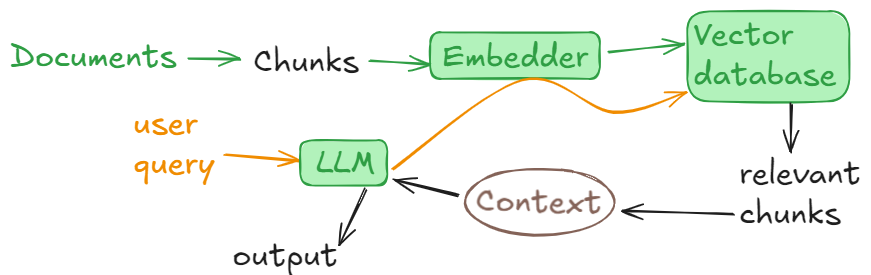
Multitudes of articles were written about that topic. Everybody knows the drill: chunked documents are stored in a vector database in the form of embeddings; when a user query appears it also undergoes the embedding procedure; based on comparison of the query embeddings vs database storage, selected chunks are compound into relevant context and submitted into LLM together with the query to get the final response.
The main points is: it is really easy to build - LangChain, LlamaIndex, GraphRAG and Semantic Kernel from Microsoft + others frameworks are available and your RAG PoC is ready in 30 lines of code, which will make it work and answer your questions, but building it is just the surface of the project work.
What can go wrong?
What can go wrong? Well, if no testing and evaluation is done - then nothing, of course… at least until stakeholders come back to you with questions.
In reality though, even SotA systems will struggle to provide you a correct answer to the same request 100% of times (reliability and consistency are key). Yet alone outdated versions like GPT3.5 which are may still be employed in enclosed corporate environments.
In other words, they will hallucinate, silently fail to parse pdf documents (especially in non-English languages), Common issues due to tokenization and embeddings still creates some challenges. I have a number of interesting cases of what can go wrong with LLMs.
And the biggest part of the job is to quantify their effect (I wrote a small separate blogpost on chatbot evaluation) and minimize it. Similar to software engineering asynchronously emerging design patterns are of great help to the community of AI developers. Some more tricks are in Advanced RAG techniques.
Patterns
Prompt
Prompt is the most basic, but very powerful instrument in our toolset. We are all doing it daily, when posting a code snippet into the chat window and adding explain code or rewrite in python. Number of examples here is limitless.
Query expansion
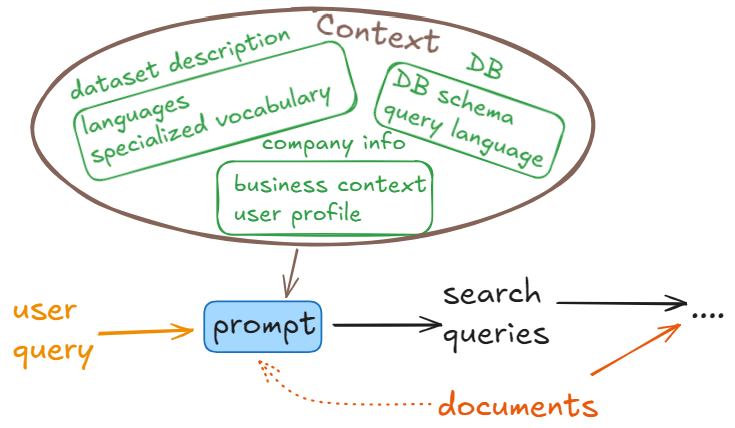
It is another promt-based pattern. Prompt is your tool, Context is your friend, Aimed to help you NOT to build a generic RAG system suitable for all possible applications. Make use of the business context, look for patterns in requests or in the data and build a solution which will perform best for this particular application. That means using the power of Context.
Expand your prompt with information about the company, business it operates, documents available in the vector database, their languages or DB schema.
Very important is to build the system for the right user group. Helpful legal AI assistant for whom? Lawyers, para-legals, their clients? Getting this wrong is like asking your chatbot to translate into the wrong language.
ask an LLM to generate one or multiple queries based on your initial query; use auto-generated queries for retrieving relevant chunks from vector database
The idea is that expanded queries are better suitable for information retrieval than the original human-written request
Query expansion can become core component to an AI product like SQL assistant or No-code UI generator
Can be done using a zero-shot learning prompt, but if good output query examples are available, these can be added
Pattern visualization
Figure
Use-cases and products
Multi-language documents in the database
SQL assistant: generating standardized query language under the hood (SQL, Cypher)
Specific vocabulary, terms, which user might not know
Any other specialized info that might help the Assistant set up a better search
Prompt example
Prompt example
You are an AI search assistant at {company_name}.
You can search for any information in the database using full-text search engine.
Information in the database is in English and {another_language}.
Given the original user query below, generate five different search phrases in order to most efficiently search in the database.
By generating multiple perspectives on the user query, your goal is to help overcome limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines.
Take into account {company_name} domain specialization
# {company_name} domain specialization
// Brief info about the industry and primary business targets.
Take into account data source specialization
# data source specialization
// Brief info about documents, database, specific terms, anything non-standard.
# original user query
"{query}"
It is not a RAG yet. More like a notebook with its own indexing system and way to find things. Information there is not searched, but pulled from.
Use cases and products
Business translator: very specialized translation tool for domains where google translate is not good enough. Knowledge base can contain language-specific tips and commonly encountered mistakes (see also Pattern Learn from feedback) per language, model, etc.
Learn from feedback
Implement an optional (human) review process in order to keep track of common mistakes made by the Assistant. Common mistakes are then added into a local Knowledge base, from which they can be added back into the Prompt as rich context. Reducing occurrence of selected mistakes can be a quality metric and engineering team’s KPI. Another modification of this pattern is REPL loop
Use cases and products
See business translator. Translation is the hardest part done by the AI assistant, but occasional brief review of resulting document can be done by humans.
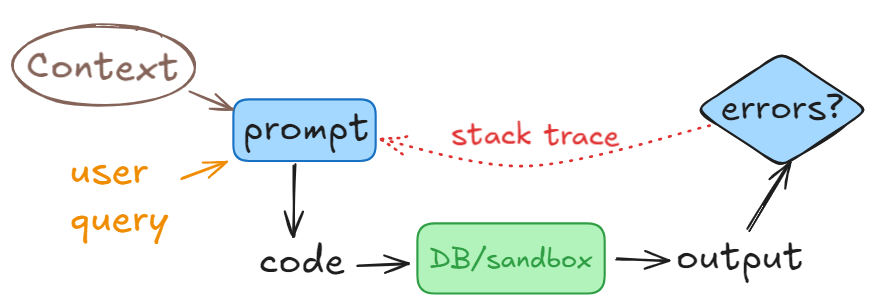
When Assistant is asked to return executable code, like text-to-sql or text-to-python-code, it is possible that the code will contain a bug.
In such case it is helpful to feed back the execution error into the original prompt and ask the Assistant to try again with this new information of what went wrong.
This pattern significantly reduced the number of cases where human involvement is needed.
NOTE
When working with sandboxes, it is crucial to prevent all kinds of malicious actions that could be done with your database - deleting, wiping out or altering data relations.
In order to do that, one must consider implementing security features on several layers:
Model instructions
Input question validation
Generated output validation
System level restrictions (e.g. read-only databases).
Alternatively, consider full sandbox isolation (Docker or Firecracker,).
Use cases and products
text-to-sql
text-to-code
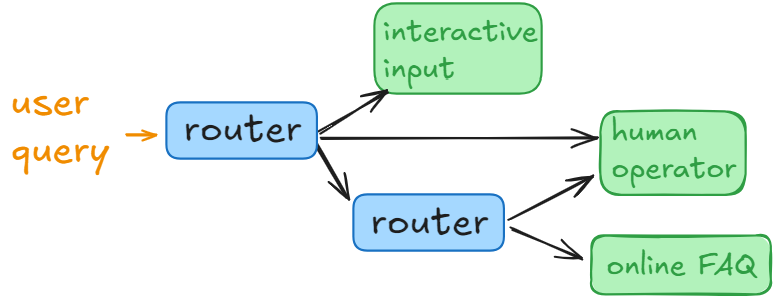
Router
Router is a prompt, which makes the LLM act as a triage model. Router pattern makes the underlying LLM act as a classification model. It is essentially a Classify this... instruction to the model to pass user request further to one of downstream services, human operators or other routers. It is absolutely possible to have hundreds or more classification categories, which makes this pattern to pair very well with Agents.
One of the challenges with routing lies in ensuring performance bottlenecks won’t happen in production.
Use cases and products
Customer support bot
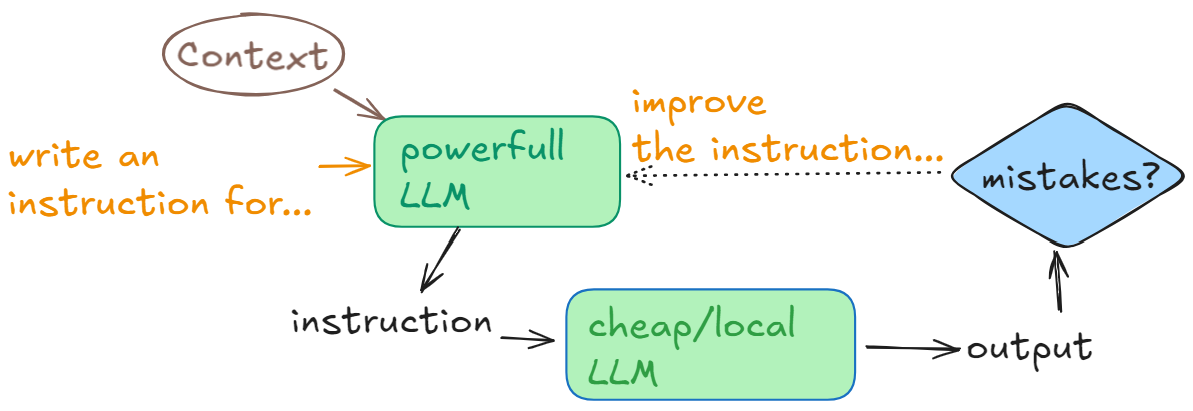
Distillation
Using the most powerful available model to write instructions for weaker models. E.g. ask GPT-4 to write a comprehensive, extended instructions such that a student/layman can understand and follow. Auto-generated instruction becomes a prompt for a weaker model. If the model does not perform satisfyingly under this prompt, it is fed back to the model with a request to make it more clear, because students can’t follow. This pattern aimed at saving time writing working prompts for non-SotA models.
Use cases and products
Adaptive customer support bot
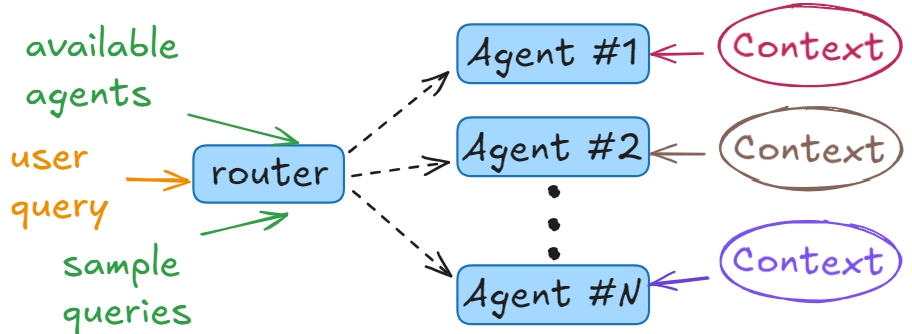
Agents
Building a one-for-all monolith system able to handle any request is hard and leads to unequal performances on different tasks. This pattern in combination with the Router makes it look like a single entry-point solution for a user, but, in reality, after the routing any given query will be handled by a specialized prompt, model, context combination. This configuration is what we call an Agent. The router has access to a list of available agents and the way to call them, as well as sample queries per agent.
Agents patter allows more precise tweaking of the system, while doing this in parallel also the overall quality of the system should improve. Keeping extensive logging, while staying compliant with any applicable regulations, may prove very helpful at a later stage of iterative improvement.
A list of agents can be extended with time either by system developers or even users themselves, through the provided API. This is very convenient as new use-cases may appear when the system is already up-and-running, but it can be updated with more agents on-the-go.
Use cases and products
Customer support
Workflow
In the Agents pattern it was assumed that each agent is solely and fully responsible for one specialized task. After the routing takes place, selected agent receives a prompt and context and should provide response directly. This may work well, but if a particular agent fails to deliver, it is usually unclear why and the only tool to improve the output is to (more or less) blindly tweak the agent’s prompt.
The workflow pattern states that each agent should be represented by the whole pipeline of actions and intermediate prompts. The pipeline, though, should be kept straightforward and any tree-structures are an indication that multiple agents should be considered instead.
Example of actions could be - downloading additional data, performing database\web search, fetching input, etc.
Use cases and products
Enterprise B2B sales assistant
Automated customer support at Fintech
Human in the Loop (HITL)
In an existing business process involving humans, identify the most repetitive, irritative, cumbersome or error-prone steps and automate them. Keep human in the loop for steps requiring more control, overview or emotional intelligence. Another name for the pattern would be cognitive load sharing.
Use cases and products
Creative content generator
Medical diagnosis
Fraud detection
Data annotation
Structured Data Extraction
The enterprise processes are built on top of the documents - invoices, all kinds of reports, emails. logs, support tickets, etc. These can also be unstructured PDFs, images, emails, web pages, etc. Very often data extraction from a document base is most labor-intensive, but also lucrative task, as once information is put into a structured form actions can be run upon it.
Tool set for data extraction include Tesseract, PyMuPDF, Unstructured, other dedicated software or dedicated LLM models (e.g. fine-tuned, with vision capabilities).
Use cases and products
Data entry automation
Invoice processing
Contract analysis
Structured Outputs & Custom CoT
Structured Outputs is a way to ensure that model responses adhere to a JSON schema. Along with a prompt we can provide a (Pydantic) response structure.
Code
from openai import OpenAIfrom pydantic import BaseModelclient = OpenAI()class CalendarEvent(BaseModel): name: str date: str participants: list[str]response = client.responses.parse( model="gpt-4o-2024-08-06", input=[ {"role": "system", "content": "Extract the event information."}, { "role": "user", "content": "Alice and Bob are going to a science fair on Friday.", }, ], text_format=CalendarEvent,)event = response.output_parsed
Model providers send the response structure to their servers, unwrap into a JSON schema, and use for constrained decoding strategy. In essence, we provide the model not only with a prompt, but also with an instruction of how to write the response. This pattern simplifies post processing of model responses, suitable for Structured Data Extraction and custom Chain-of-Thought: via requested format it is possible to make model think in steps or provide links to relevant sources\pages\citations.
Resources
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"