Evolution of embeddings
scroll ↓ to Resources
Contents
- Note
- Evolution of embeddings
- [[#Evolution of embeddings#Word Embeddings|Word Embeddings]]
- [[#Evolution of embeddings#Document embeddings|Document embeddings]]
- [[#Document embeddings#Bag-of-Words models and shallow neural networks|Bag-of-Words models and shallow neural networks]]
- [[#Document embeddings#Deeper neural networks|Deeper neural networks]]
- [[#Evolution of embeddings#Image & multimodal embeddings|Image & multimodal embeddings]]
- [[#Evolution of embeddings#Structured data embeddings|Structured data embeddings]]
- [[#Evolution of embeddings#Graph embeddings|Graph embeddings]]
- Resources
Note
Evolution of embeddings
Word Embeddings
- lightweight, context-free word embedding
- Word2Vec
- operates on the principle of “the semantic meaning of a word is defined by its neighbors”, or words that frequently appear close to each other in the training corpus
- it accounts well for local statistics of words within a certain sliding window, but it does not capture the global statistics (words in the whole corpus)
- GloVe
- leverages both global and local statistics of words
- Creates a co-occurrence matrix which represents the relationship between words and then uses factorization technique to learn word representations from this matrix.
- SWIVEL ( Skip-Window Vectors with Negative Sampling)
Document embeddings
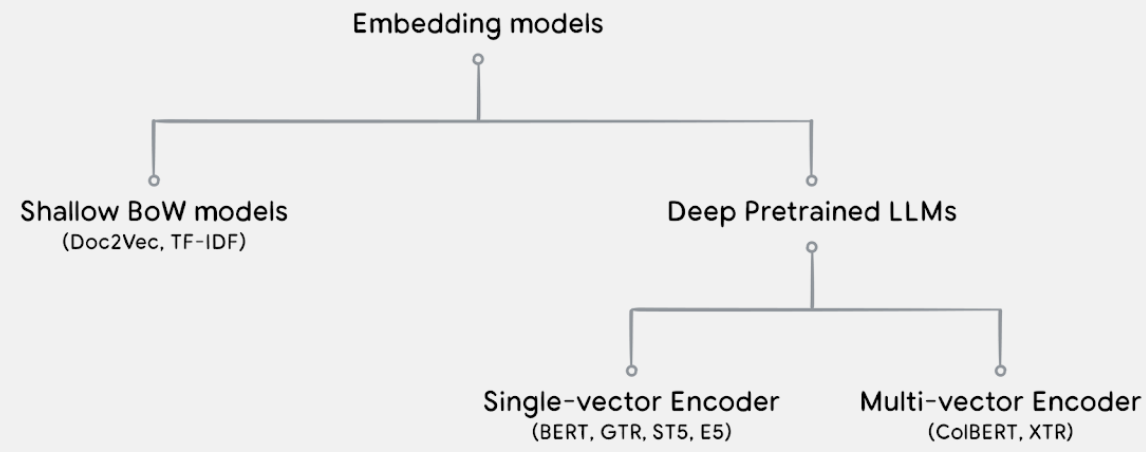
Bag-of-Words models and shallow neural networks
- Early embedding algorithms based on shallow Bag-of-Words models paradigm assumed that a document is an unordered collection of words.
- Latent Semantic Analysis (LSA)
- Latent Dirichlet Allocation (LDA)
- TF-IDF models are statistical models that use the word frequency to represent the document embeddings. BM25, a TF-IDF-based bag-of-words model, is still a strong baseline in today’s retrieval benchmarks
- the word ordering and the semantic meanings are ignored
- Doc2Vec use shallow neural network for generating document embedding
Deeper neural networks
- BERT became the base model for multiple other embedding models - Sentence BERT, SimCSE, E5
- More complex bi-directional deep NN
- Massive pre-training on unlabeled data with masked language model as the objective to utilize left and right context
- Sub-word tokenizer
- Outputs a contextualized embedding for every token in the input, but the embedding of the first token, named [CLS], is used as the embedding for the whole input.
- T5 with 11B parameters
- PaLM with 540B parameters
- Model families generating multi-vector embedding ColBERT, XTR
Image & multimodal embeddings
- dedicated image embedding model
- image captioning model
- image ⇒ caption ⇒ text embedding
Structured data embeddings
Graph embeddings
Resources
Transclude of base---related.base
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"