direct preference optimization
scroll ↓ to Resources
Note
- part of the post-training approach as in ^8e9af4
Comparison to RLHF
- alternative to RLHF for model alignment
- because the RLHF can be seen as unstable and complex procedure requiring fitting a reward model to collected relative human preferences data and then fine-tuning the large self-supervised LM using reinforcement learning to maximize the estimated reward without drifting too far from the original model
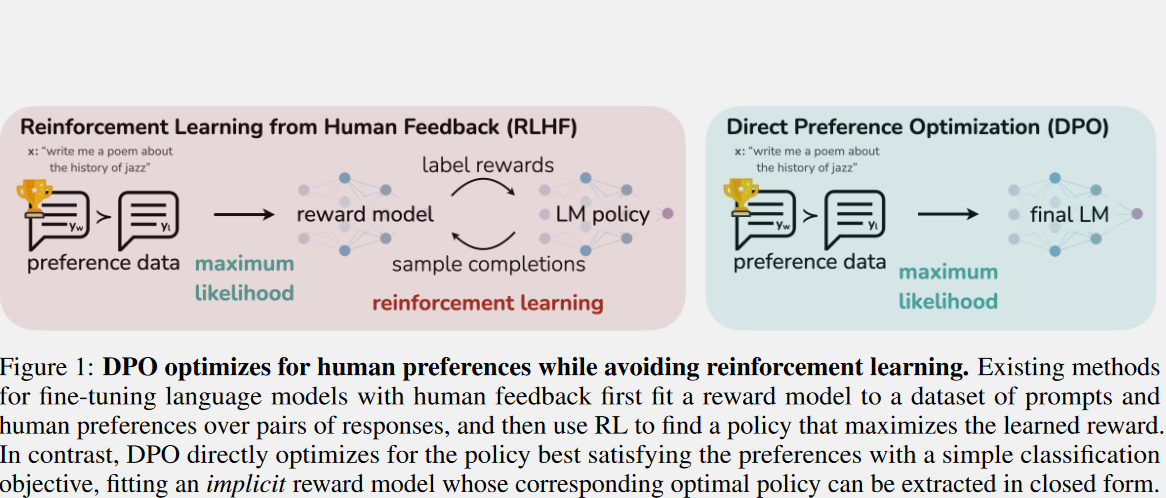
the idea behind the DPO
- instead of creating a proxy reward model, generating new outputs, scoring them and, finally, maximizing the probability of generating high-scored outputs ==DPO allows fine-tuning a LM directly on human preference data using backpropagation==
- Uses some math to suggest an internal reward model that doesn’t take into account human preferences. It turns out to be very simple and it roughly says: “A continuation yy is better for a prompt xx if yy is more likely to be generated from xx by the LLM”.
- It then takes the
(prompt, preferred_continuation, rejected_continuation)dataset and trains the LLM on it in a simple supervised way to ensure that, roughly speaking, the preferred continuation is more likely to be generated from the prompt than the rejected one*.
Resources
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"