Reinforcement Learning from Human Feedback
scroll ↓ to Resources
Note
- RLHF is not the name of a particular algorithm. Rather, it’s a particular task formulation where the reward used in training (reward model) is an approximation of the “true” reward, which lives in the human minds (that is, real human preferences).
- core idea is to generate several outputs (for each query) using a pre-trained model, ask human annotators to rank them
- then, depending on the approach
- in PPO - train a special reward model, which is able to predict human ranking of unseen generated outputs. then train the LLM further by asking it to maximized the reward
- in DPO - directly train the model using collected labeled data, without an explicit reward modeling step
- then, depending on the approach
- Reinforcement Learning is a capricious tool, so there have been several attempts at getting rid of it for alignment training. The most popular one right now is Direct Preference Optimization.
the RLHF pipeline
-
usually consists of 3 phases:
- supervised finetuning (SFT): fine-tuning a pre-trained LM with supervised learning on high-quality data for the downstream task(s) of interest (dialogue, summarization, etc.), to obtain a model (in order to make it generate reasonable quality output for RLHF)
- preference sampling and reward modeling: create a model predicting the score, which COULD BE given by a human
- see more in 4.1.2 Reward Modeling (RM)
- this saves a lot of labeling effort, provides a metric to optimize
- reinforcement learning optimization: the learned reward function is used to provide feedback to the language mode
-
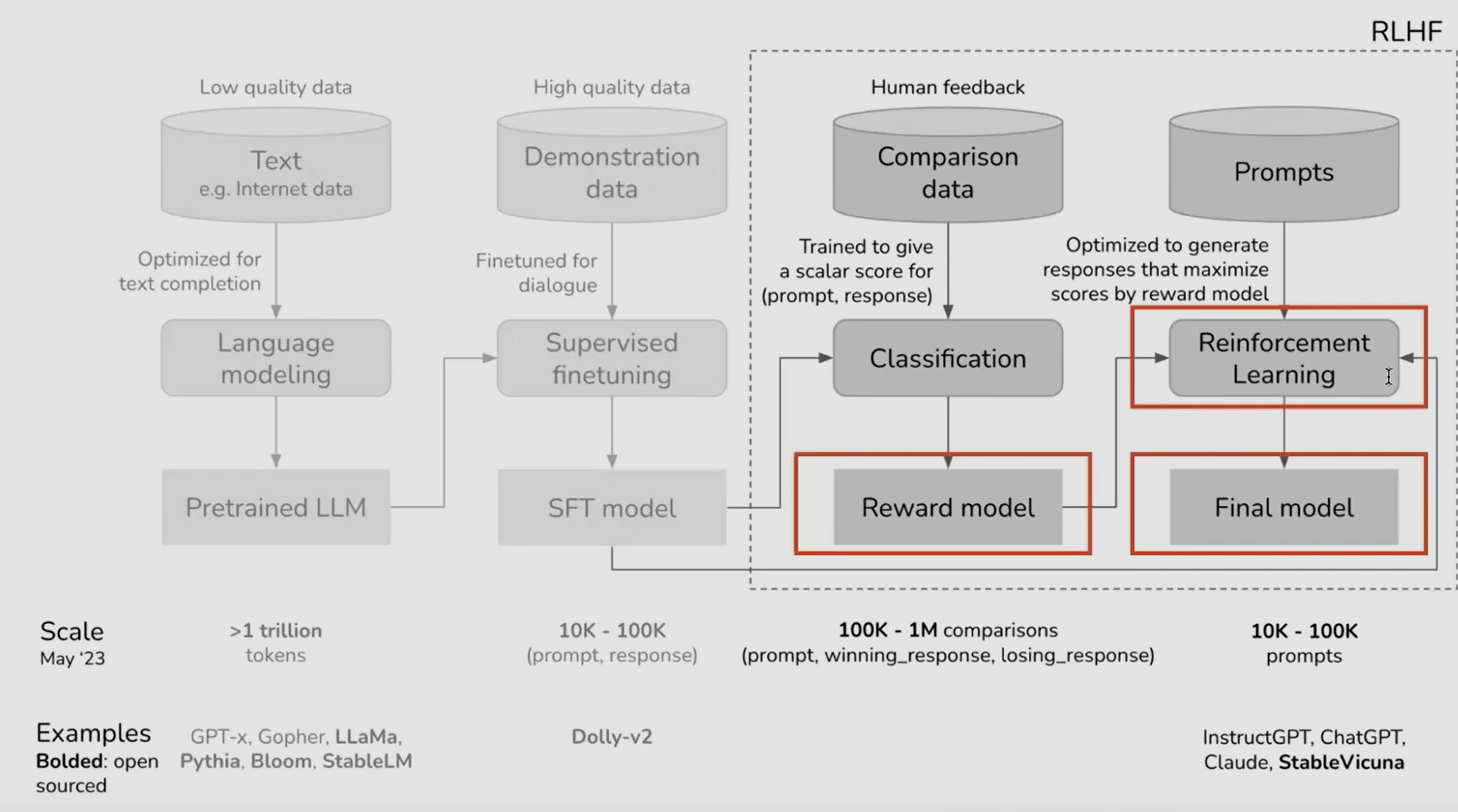
reinforcement learning finetuning phase
- the optimization is formulated as

where dist is some kind of distance; Kullback-Leibler divergence between the predicted probability distributions is popular in this role. This way, we maximize the reward while keeping the distance low.
- same formula written as in the DPO paper:

- RLHF fine-tuning doesn’t require pairs
(prompt, completion)for training. The dataset for RLHF consists of prompts only, and the completions are generated by the model itself as part of the trial-and-error. - While RLHF improves alignment with human preferences, it doesn’t directly optimize output correctness and plausibility. This means that alignment training can harm the LLM quality. So while a model that refuses to answer any question will never tell a user how to make a chemical weapon so it’s perfectly harmless – although still utterly useless for helpful purposes, too. To address this issue, we try to ensure that the RLHF-trained model doesn't diverge much from its SFT predecessor. This is often enforced by adding a regularization term to the optimized function.
- This way the output model also operates within the x-y space, where the reward model was trained and, therefore, where it is reasonably accurate.
- It also prevents model collapse to single high reward answers.
Resources
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"